 A few weeks ago, I read in the NYT an article about the American Academy of Religion cancelling its 2021 annual meeting as a sabbatical year, for environmental reasons.
A few weeks ago, I read in the NYT an article about the American Academy of Religion cancelling its 2021 annual meeting as a sabbatical year, for environmental reasons.
“We could choose to not meet at a huge annual meeting in which we take over a city. Every year, each participant going to the meeting uses a quantum of carbon that is more than considerable. Air travel, staying in hotels, all of this creates a way of living on the Earth that is carbon intensive. It could be otherwise.”
While I am not in the least interested in the conference or in the topics covered by this society or yet in the benevolent religious activities suggested as a substitute, the notion of cancelling the behemoths that are our national and international academic meetings holds some appeal. I have posted several times on the topic, especially about JSM, and I have no clear and definitive answer to the question. Still, there lies a lack of efficiency on top of the environmental impact that we could and should try to address.  As I was thinking of those issues in the past week, I made another of my numerous “carbon footprints” by attending NIPS across the Atlantic for two workshops than ran in parallel with about twenty others. And hence could have taken place in twenty different places. Albeit without the same exciting feeling of constant intellectual simmering. And without the same mix of highly interactive scholars from all over the planet. (Although the ABC in Montréal workshop seemed predominantly European!) Since workshops are in my opinion the most profitable type of meeting, I would like to experiment with a large meeting made of those (focussed and intense) workshops in such a way that academics would benefit without travelling long distances across the World. One idea would be to have local nodes where a large enough group of researchers could gather to attend video-conferences given from any of the other nodes and to interact locally in terms of discussions and poster presentations. This should even increase the feedback on selected papers as small groups would more readily engage into discussing and criticising papers than a huge conference room. If we could build a World-wide web (!) of such nodes, we could then dream of a non-stop conference, with no central node, no gigantic conference centre, no terrifying beach-ressort…
As I was thinking of those issues in the past week, I made another of my numerous “carbon footprints” by attending NIPS across the Atlantic for two workshops than ran in parallel with about twenty others. And hence could have taken place in twenty different places. Albeit without the same exciting feeling of constant intellectual simmering. And without the same mix of highly interactive scholars from all over the planet. (Although the ABC in Montréal workshop seemed predominantly European!) Since workshops are in my opinion the most profitable type of meeting, I would like to experiment with a large meeting made of those (focussed and intense) workshops in such a way that academics would benefit without travelling long distances across the World. One idea would be to have local nodes where a large enough group of researchers could gather to attend video-conferences given from any of the other nodes and to interact locally in terms of discussions and poster presentations. This should even increase the feedback on selected papers as small groups would more readily engage into discussing and criticising papers than a huge conference room. If we could build a World-wide web (!) of such nodes, we could then dream of a non-stop conference, with no central node, no gigantic conference centre, no terrifying beach-ressort…
 Since
Since  and
and  missing from the first model)
missing from the first model)
 is an arbitrary normalised density on
is an arbitrary normalised density on 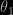 , and
, and  is an arbitrary function, we have the bridge sampling identity on
is an arbitrary function, we have the bridge sampling identity on  :
:

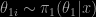 and
and  . More exactly, this approximation is replaced with an iterative version since it depends on the unknown
. More exactly, this approximation is replaced with an iterative version since it depends on the unknown  is obviously fundamental and it should be close to the true posterior
is obviously fundamental and it should be close to the true posterior 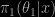 to guarantee good convergence approximation. Using a normal approximation to the posterior distribution of
to guarantee good convergence approximation. Using a normal approximation to the posterior distribution of 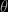 or a non-parametric approximation based on a sample from
or a non-parametric approximation based on a sample from  , or yet again an average of MCMC proposals are reasonable choices.
, or yet again an average of MCMC proposals are reasonable choices.
 have to be introduced), with
have to be introduced), with 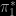 (using a normal centred at the estimate of the missing parameter, and with variance the estimate from the simulation), when testing whether or not the mean of a normal model with unknown variance is zero. The variabilities are quite comparable in this admittedly overly simple case. Overall, the performances of both extensions are obviously highly dependent on the choice of the completion factors,
(using a normal centred at the estimate of the missing parameter, and with variance the estimate from the simulation), when testing whether or not the mean of a normal model with unknown variance is zero. The variabilities are quite comparable in this admittedly overly simple case. Overall, the performances of both extensions are obviously highly dependent on the choice of the completion factors, 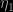 and
and 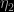 on the one hand and
on the one hand and 
 Wikipedia")

Comments for València 9
Posted in Statistics, University life with tags Benidorm, comments, discussions, simulations, Valencia 9 on June 23, 2010 by xi'anBernardo, José M. (Universitat de València, Spain)
Integrated objective Bayesian estimation and hypothesis testing. [discussion]
Consonni, Guido (Università di Pavia, Italy)
On moment priors for Bayesian model choice with applications to directed acyclic graphs. [discussion]
Frühwirth-Schnatter, Sylvia (Johannes Kepler Universität Linz, Austria)
Bayesian variable selection for random intercept modeling of Gaussian and non-Gaussian data. [discussion]
Huber, Mark (Claremont McKenna College, USA)
Using TPA for Bayesian inference. [discussion]
Lopes, Hedibert (University of Chicago, USA)
Particle learning for sequential Bayesian computation. [discussion]
Polson, Nicholas (University of Chicago, USA)
Shrink globally, act locally: Sparse Bayesian regularization and prediction. [discussion]
Wilkinson, Darren (University of Newcastle, UK)
Parameter inference for stochastic kinetic models of bacterial gene regulation: a Bayesian approach to systems biology. [discussion]
(with a possible incoming update on Mark Huber’s comments if we manage to get the simulations running in due time).
Share:
9 Comments »