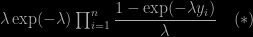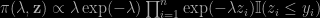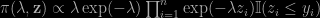A few months ago, as indicated on this blog, I was contacted by ISR editors to write a piece on Rao-Blackwellisation, towards a special issue celebrating Calyampudi Radhakrishna Rao’s 100th birthday. Gareth Roberts and I came up with this survey, now on arXiv, discussing different aspects of Monte Carlo and Markov Chain Monte Carlo that pertained to Rao-Blackwellisation, one way or another. As I discussed the topic with several friends over the Fall, it appeared that the difficulty was more in setting the boundaries. Than in finding connections. In a way anything conditioning or demarginalising or resorting to auxiliary variates is a form of Rao-Blackwellisation. When re-reading the JASA Gelfand and Smith 1990 paper where I first saw the link between the Rao-Blackwell theorem and simulation, I realised my memory of it had drifted from the original, since the authors proposed there an approximation of the marginal based on replicas rather than the original Markov chain. Being much closer to Tanner and Wong (1987) than I thought. It is only later that the true notion took shape. [Since the current version is still a draft, any comment or suggestion would be most welcomed!]