
Archive for Monte Carlo integration
In the paper there is y instead of x
Posted in Books, Kids, Statistics, University life with tags cross validated, importance sampling, infinite variance estimators, Monte Carlo integration, reference on October 17, 2023 by xi'an
powering a probability [a Bernoulli factory tale]
Posted in Books, R, Statistics with tags Bernoulli factory, cross validated, Monte Carlo integration on April 21, 2023 by xi'anStarting from an X validated question on finding an unbiased estimator of an integral raised to a non-integer power, I came across a somewhat interesting Bernoulli factory solution! Thanks to Peter Occil’s encyclopedic record of cases, pointing out to Mendo’s (2019) solution for functions of ρ that can be expressed as power series. Like ργ since
![(1-[1-\rho])^\gamma=1+\gamma(1-\rho)+\frac{\gamma(\gamma-1)(1-\rho)^2}{2}+\cdots](https://s0.wp.com/latex.php?latex=%281-%5B1-%5Crho%5D%29%5E%5Cgamma%3D1%2B%5Cgamma%281-%5Crho%29%2B%5Cfrac%7B%5Cgamma%28%5Cgamma-1%29%281-%5Crho%29%5E2%7D%7B2%7D%2B%5Ccdots&bg=000000&fg=B0B0B0&s=0&c=20201002)
which rather magically turns into the reported algorithm
Set k=1 Repeat the following process, until it returns a value x: 1. Generate a Bernoulli B(ϱ) variate z; if z=1, return x=1 2. Else, with probability γ/k, return x=0 3. Else, set k=k+1 and return to 1.
since
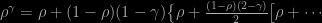
noisy importance sampling
Posted in Statistics with tags approximate Bayesian inference, approximate likelihood, importance sampling, Monte Carlo integration on February 14, 2022 by xi'anA recent short arXival by Fernando Llorente, Luca Martino, Jesse Read, and David Delgado–Gómez in which they analyse settings where (only) a noisy version of the target density is available. Not necessarily in an unbiased fashion although the paper is somewhat unclear as to which integral is targeted in (6), since the integrand is not the original target p(x). The following development is about finding the optimal importance function, which differs from the usual due to the random nature of the approximation, but it does not seem to reconnect with the true target p(x), except when the noisy realisation is unbiased… To me this is a major issue in simulation methodology in that getting away from the unbiasedness constraint opens (rather obviously) a much wider choice of techniques.
what if what???
Posted in Books, Statistics with tags Markov chain Monte Carlo algorithm, MCMC, Monte Carlo integration, Monte Carlo methods, what if?, wikipedia on October 7, 2019 by xi'an[Here is a section of the Wikipedia page on Monte Carlo methods which makes little sense to me. What if it was not part of this page?!]
Monte Carlo simulation versus “what if” scenarios
There are ways of using probabilities that are definitely not Monte Carlo simulations – for example, deterministic modeling using single-point estimates. Each uncertain variable within a model is assigned a “best guess” estimate. Scenarios (such as best, worst, or most likely case) for each input variable are chosen and the results recorded.[55]
By contrast, Monte Carlo simulations sample from a probability distribution for each variable to produce hundreds or thousands of possible outcomes. The results are analyzed to get probabilities of different outcomes occurring.[56] For example, a comparison of a spreadsheet cost construction model run using traditional “what if” scenarios, and then running the comparison again with Monte Carlo simulation and triangular probability distributions shows that the Monte Carlo analysis has a narrower range than the “what if” analysis. This is because the “what if” analysis gives equal weight to all scenarios (see quantifying uncertainty in corporate finance), while the Monte Carlo method hardly samples in the very low probability regions. The samples in such regions are called “rare events”.
a new rule for adaptive importance sampling
Posted in Books, Statistics with tags adaptive importance sampling, AMIS, empirical likelihood, Helsinki, MCMC, Monte Carlo integration, Monte Carlo Statistical Methods, multiple importance methods, pseudo-random generators, University of Warwick on March 5, 2019 by xi'anArt Owen and Yi Zhou have arXived a short paper on the combination of importance sampling estimators. Which connects somehow with the talk about multiple estimators I gave at ESM last year in Helsinki. And our earlier AMIS combination. The paper however makes two important assumptions to reach optimal weighting, which is inversely proportional to the variance:
- the estimators are uncorrelated if dependent;
- the variance of the k-th estimator is of order a (negative) power of k.
The later is puzzling when considering a series of estimators, in that k appears to act as a sample size (as in AMIS), the power is usually unknown but also there is no reason for the power to be the same for all estimators. The authors propose to use ½ as the default, both because this is the standard Monte Carlo rate and because the loss in variance is then minimal, being 12% larger.
As an aside, Art Owen also wrote an invited discussion “the unreasonable effectiveness of Monte Carlo” of ” Probabilistic Integration: A Role in Statistical Computation?” by François-Xavier Briol, Chris Oates, Mark Girolami (Warwick), Michael Osborne and Deni Sejdinovic, to appear in Statistical Science, discussion that contains a wealth of smart and enlightening remarks. Like the analogy between pseudo-random number generators [which work unreasonably well!] vs true random numbers and Bayesian numerical integration versus non-random functions. Or the role of advanced bootstrapping when assessing the variability of Monte Carlo estimates (citing a paper of his from 1992). Also pointing out at an intriguing MCMC paper by Michael Lavine and Jim Hodges to appear in The American Statistician.
