 The nice logo of MCqMC 2016 was a collection of eight series of QMC dots on the unit (?) cube. The organisers set a competition to identify the principles behind those quasi-random sets and as I had no idea for most of them I entered very random sets unconnected with algorithmia, for which I got an honourable mention and a CD prize (if not the conference staff tee-shirt I was coveting!) Art Owen sent me back my entry, posted below and hopefully (or not!) readable.
The nice logo of MCqMC 2016 was a collection of eight series of QMC dots on the unit (?) cube. The organisers set a competition to identify the principles behind those quasi-random sets and as I had no idea for most of them I entered very random sets unconnected with algorithmia, for which I got an honourable mention and a CD prize (if not the conference staff tee-shirt I was coveting!) Art Owen sent me back my entry, posted below and hopefully (or not!) readable.
Archive for uniformity
winning entry at MCqMC’16
Posted in Books, Kids, pictures, Statistics, Travel, University life with tags California, MCqMC 2016, qMC, quasi-random sequences, scientific computing, Stanford University, tee-shirt, uniformity on August 29, 2016 by xi'anPosterior predictive p-values and the convex order
Posted in Books, Statistics, University life with tags Andrew Gelman, arXiv, Bayesian p-values, DIC, posterior predictive, uniformity, University of Bristol, using the data twice, warhammer, Xiao-Li Meng on December 22, 2014 by xi'anPatrick Rubin-Delanchy and Daniel Lawson [of Warhammer fame!] recently arXived a paper we had discussed with Patrick when he visited Andrew and I last summer in Paris. The topic is the evaluation of the posterior predictive probability of a larger discrepancy between data and model

which acts like a Bayesian p-value of sorts. I discussed several times the reservations I have about this notion on this blog… Including running one experiment on the uniformity of the ppp while in Duke last year. One item of those reservations being that it evaluates the posterior probability of an event that does not exist a priori. Which is somewhat connected to the issue of using the data “twice”.
“A posterior predictive p-value has a transparent Bayesian interpretation.”
Another item that was suggested [to me] in the current paper is the difficulty in defining the posterior predictive (pp), for instance by including latent variables

which reminds me of the multiple possible avatars of the BIC criterion. The question addressed by Rubin-Delanchy and Lawson is how far from the uniform distribution stands this pp when the model is correct. The main result of their paper is that any sub-uniform distribution can be expressed as a particular posterior predictive. The authors also exhibit the distribution that achieves the bound produced by Xiao-Li Meng, Namely that
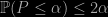
where P is the above (top) probability. (Hence it is uniform up to a factor 2!) Obviously, the proximity with the upper bound only occurs in a limited number of cases that do not validate the overall use of the ppp. But this is certainly a nice piece of theoretical work.
Random sudokus [p-values]
Posted in R, Statistics with tags combinatorics, entropy, Kullback, Monte Carlo, p-value, simulation, sudoku, uniformity on May 21, 2010 by xi'an I reran the program checking the distribution of the digits over 9 “diagonals” (obtained by acceptable permutations of rows and column) and this test again results in mostly small p-values. Over a million iterations, and the nine (dependent) diagonals, four p-values were below 0.01, three were below 0.1, and two were above (0.21 and 0.42). So I conclude in a discrepancy between my (full) sudoku generator and the hypothesised distribution of the (number of different) digits over the diagonal. Assuming my generator is a faithful reproduction of the one used in the paper by Newton and DeSalvo, this discrepancy suggests that their distribution over the sudoku grids do not agree with this diagonal distribution, either because it is actually different from uniform or, more likely, because the uniform distribution I use over the (groups of three over the) diagonal is not compatible with a uniform distribution over all sudokus…
I reran the program checking the distribution of the digits over 9 “diagonals” (obtained by acceptable permutations of rows and column) and this test again results in mostly small p-values. Over a million iterations, and the nine (dependent) diagonals, four p-values were below 0.01, three were below 0.1, and two were above (0.21 and 0.42). So I conclude in a discrepancy between my (full) sudoku generator and the hypothesised distribution of the (number of different) digits over the diagonal. Assuming my generator is a faithful reproduction of the one used in the paper by Newton and DeSalvo, this discrepancy suggests that their distribution over the sudoku grids do not agree with this diagonal distribution, either because it is actually different from uniform or, more likely, because the uniform distribution I use over the (groups of three over the) diagonal is not compatible with a uniform distribution over all sudokus…
Random [uniform?] sudokus [corrected]
Posted in R, Statistics with tags combinatorics, correction, Monte Carlo, simulation, sudoku, uniformity on May 19, 2010 by xi'anAs the discrepancy [from 1] in the sum of the nine probabilities seemed too blatant to be attributed to numerical error given the problem scale, I went and checked my R code for the probabilities and found a choose(9,3) instead of a choose(6,3) in the last line… The fit between the true distribution and the observed frequencies is now much better
 but the chi-square test remains suspicious of the uniform assumption (or again of my programming abilities):
but the chi-square test remains suspicious of the uniform assumption (or again of my programming abilities):
> chisq.test(obs,p=pdiag)
Chi-squared test for given probabilities
data: obs
X-squared = 16.378, df = 6, p-value = 0.01186
since a p-value of 1% is a bit in the far tail of the distribution.
Random [uniform?] sudokus
Posted in R, Statistics with tags combinatorics, entropy, Kullback, Monte Carlo, simulation, sudoku, uniformity on May 19, 2010 by xi'anA longer run of the R code of yesterday with a million sudokus produced the following qqplot.
 It does look ok but no perfect. Actually, it looks very much like the graph of yesterday, although based on a 100-fold increase in the number of simulations. Now, if I test the adequation with a basic chi-square test (!), the result is highly negative:
It does look ok but no perfect. Actually, it looks very much like the graph of yesterday, although based on a 100-fold increase in the number of simulations. Now, if I test the adequation with a basic chi-square test (!), the result is highly negative:
> chisq.test(obs,p=pdiag/sum(pdiag)) #numerical error in pdiag
Chi-squared test for given probabilities
data: obs
X-squared = 6978.503, df = 6, p-value < 2.2e-16
(there are seven entries for both obs and pdiag, hence the six degrees of freedom). So this casts a doubt upon the uniformity of the random generator suggested in the paper by Newton and DeSalvo or rather on my programming abilities, see next post!
