
Archive for black box
rigour, imagination and production in London
Posted in Statistics, Travel, University life with tags Alan Turing Institute, Andrew Gelman, black box, Great-Britain, Kings College London, London, paradigm shift, public lecture, Theory and Method Challenge Fortnights 2024 on June 16, 2024 by xi'an
black box MCMC
Posted in Books, Statistics with tags AISTATS 2017, black box, Charles Stein, control variates, importance sampling, integration by parts, MCMC, unadjusted Langevin algorithm, unbiased es on July 17, 2021 by xi'an
“…back-box methods, despite using no information of the proposal distribution, can actually give better estimation accuracy than the typical importance sampling [methods]…”
Earlier this week I was pointed out to Liu & Lee’s black box importance sampling, published in AISTATS 2017. (which I did not attend). Already found in Briol et al. (2015) and Oates, Girolami, and Chopin (2017), the method starts from Charles Stein‘s “unbiased estimator of the loss” (that was a fundamental tool in my own PhD thesis!), a variation on integration by part:
![\mathbb E_p[\nabla\log p(X) f(X)+\nabla f(X)]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E_p%5B%5Cnabla%5Clog+p%28X%29+f%28X%29%2B%5Cnabla+f%28X%29%5D%3D0&bg=000000&fg=B0B0B0&s=0&c=20201002)
for differentiable functions f and p cancelling at the boundaries. It also holds for the kernelised extension
![\mathbb E_p[k_p(X,x')]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E_p%5Bk_p%28X%2Cx%27%29%5D%3D0&bg=000000&fg=B0B0B0&s=0&c=20201002)
for all x’, where the integrand is a 1-d function of an arbitrary kernel k(x,x’) and of the score function ∇log p. This null expectation happens to be a minimum since
![\mathbb E_{X,X'\sim q}[k_p(X,X')]\ge 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E_%7BX%2CX%27%5Csim+q%7D%5Bk_p%28X%2CX%27%29%5D%5Cge+0&bg=000000&fg=B0B0B0&s=0&c=20201002)
and hence importance weights can be obtained by minimising
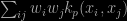
in w (from the unit simplex), for a sample of iid realisations from a possibly unknown distribution with density q. Liu & Lee show that this approximation converges faster than the standard Monte Carlo speed √n, when using Hilbertian properties of the kernel through control variates. Actually, the same thing happens when using a (leave-one-out) non-parametric kernel estimate of q rather than q. At least in theory.
“…simulating n parallel MCMC chains for m steps, where the length m of the chains can be smaller than what is typically used in MCMC, because it just needs to be large enough to bring the distribution `roughly’ close to the target distribution”
A practical application of the concept is suggested in the above quote. As a corrected weight for interrupted MCMC. Or when using an unadjusted Langevin algorithm. Provided the minimisation of the objective quadratic form is fast enough, the method can thus be used as a benchmark for regular MCMC implementation.
no dichotomy between efficiency and interpretability
Posted in Books, Statistics, Travel, University life with tags AABI, black box, British Columbia, Canada, conference, credit scoring, data challenge, Harvard Data Science Review, HDSR, machine learning, NeurIPS 2019, overfitting, Vancouver on December 18, 2019 by xi'an
“…there are actually a lot of applications where people do not try to construct an interpretable model, because they might believe that for a complex data set, an interpretable model could not possibly be as accurate as a black box. Or perhaps they want to preserve the model as proprietary.”
One article I found quite interesting in the second issue of HDSR is “Why are we using black box models in AI when we don’t need to? A lesson from an explainable AI competition” by Cynthia Rudin and Joanna Radin, which describes the setting of a NeurIPS competition last year, the Explainable Machine Learning Challenge, of which I was blissfully unaware. The goal was to construct an operational black box predictor fpr credit scoring and turn it into something interpretable. The authors explain how they built instead a white box predictor (my terms!), namely a linear model, which could not be improved more than marginally by a black box algorithm. (It appears from the references that these authors have a record of analysing black-box models in various setting and demonstrating that they do not always bring more efficiency than interpretable versions.) While this is but one example and even though the authors did not win the challenge (I am unclear why as I did not check the background story, writing on the plane to pre-NeuriPS 2019).
I find this column quite refreshing and worth disseminating, as it challenges the current creed that intractable functions with hundreds of parameters will always do better, if only because they are calibrated within the box and have eventually difficulties to fight over-fitting within (and hence under-fitting outside). This is also a difficulty with common statistical models, but having the ability to construct error evaluations that show how quickly the prediction efficiency deteriorates may prove the more structured and more sparsely parameterised models the winner (of real world competitions).
machines learning but not teaching…
Posted in Books, pictures with tags AIs, artificial intelligence, black box, brain imaging, deep learning, machine learning, Nature, neural network on October 28, 2016 by xi'an
A few weeks after the editorial “Algorithms and Blues“, Nature offers another (general public) entry on AIs and their impact on society, entitled “The Black Box of AI“. The call is less on open source AIs and more on accountability, namely the fact that decisions produced by AIS and impacting people one way or another should be accountable. Rather than excused by the way out “the computer said so”. What the article exposes is how (close to) impossible this is when the algorithms are based on black-box structures like neural networks and other deep-learning algorithms. While optimised to predict as accurately as possible one outcome given a vector of inputs, hence learning in that way how the inputs impact this output [in the same range of values], these methods do not learn in a more profound way in that they very rarely explain why the output occurs given the inputs. Hence, given a neural network that predicts go moves or operates a self-driving car, there is a priori no knowledge to be gathered from this network about the general rules of how humans play go or drive cars. This rather obvious feature means that algorithms that determine the severity of a sentence cannot be argued as being rational and hence should not be used per se (or that the judicial system exploiting them should be sued). The article is not particularly deep (learning), but it mentions a few machine-learning players like Pierre Baldi, Zoubin Ghahramani and Stéphane Mallat, who comments on the distance existing between those networks and true (and transparent) explanations. And on the fact that the human brain itself goes mostly unexplained. [I did not know I could include such dynamic images on WordPress!]
