 This morning session at the workshop Recent Advances in statistical inference: theory and case studies was a true blessing for anyone working in Bayesian model choice! And it did give me ideas to complete my current paper on the Jeffreys-Lindley paradox, and more. Attending the talks in the historical Gioachino Rossini room of the fabulous Café Pedrocchi with the Italian spring blue sky as a background surely helped! (It is only beaten by this room of Ca’Foscari overlooking the Gran Canale where we had a workshop last Fall…)
This morning session at the workshop Recent Advances in statistical inference: theory and case studies was a true blessing for anyone working in Bayesian model choice! And it did give me ideas to complete my current paper on the Jeffreys-Lindley paradox, and more. Attending the talks in the historical Gioachino Rossini room of the fabulous Café Pedrocchi with the Italian spring blue sky as a background surely helped! (It is only beaten by this room of Ca’Foscari overlooking the Gran Canale where we had a workshop last Fall…)
First, Phil Dawid gave a talk on his current work with Monica Musio (who gave a preliminary talk on this in Venezia last fall) on the use of new score functions to compare statistical models. While the regular Bayes factor is based on the log score, comparing the logs of the predictives at the observed data, different functions of the predictive q can be used, like the Hyvärinen score
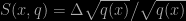
which offers the immense advantage of being independent of the normalising constant and hence can also be used for improper priors. As written above, a very deep finding that could at last allow for the comparison of models based on improper priors without requiring convoluted constructions (see below) to make the “constants meet”. I first thought the technique was suffering from the same shortcoming as Murray Aitkin’s integrated likelihood, but I eventually figured out (where) I was wrong!
The second talk was given by Ed George, who spoke on his recent research with Veronika Rocková dealing with variable selection via an EM algorithm that proceeds much much faster to the optimal collection of variables, when compared with the DMVS solution of George and McCulloch (JASA, 1993). (I remember discussing this paper with Ed in Laramie during the IMS meeting in the summer of 1993.) This resurgence of the EM algorithm in this framework is both surprising (as the missing data structure represented by the variable indicators could have been exploited much earlier) and exciting, because it opens a new way to explore the most likely models in this variable selection setting and to eventually produce the median model of Berger and Barbieri (Annals of Statistics, 2004). In addition, this approach allows for a fast comparison of prior modellings on the missing variable indicators, showing in some examples a definitive improvement brought by a Markov random field structure. Given that it also produces a marginal posterior density on the indicators, values of hyperparameters can be assessed, escaping the Jeffreys-Lindley paradox (which was clearly a central piece of today’s talks and discussions). I would like to see more details on the MRF part, as I wonder which structure is part of the input and which one is part of the inference.
The third talk of the morning was Susie Bayarri’s, about a collection of desiderata or criteria for building an objective prior in model comparison and achieving a manageable closed-form solution in the case of the normal linear model. While I somehow disagree with the information criterion, which states that the divergence of the likelihood ratio should imply a corresponding divergence of the Bayes factor. While I definitely agree with the invariance argument leading to using the same (improper) prior over parameters common to models under comparison, this may sound too much of a trick to outsiders, especially when accounting for the score solution of Dawid and Musio. Overall, though, I liked the outcome of a coherence reference solution for linear models that could clearly be used as a default in this setting, esp. given the availability of an R package called BayesVarSel. (Even if I also like our simpler solution developped in the incoming edition of Bayesian Core, also available in the bayess R package!) In his discussion, Guido Consonni highlighted the philosophical problem of considering “common paramaters”, a perspective I completely subscribe to, even though I think all that matters is the justification of having a common prior over formally equivalent parameters, even though this may sound like a pedantic distinction to many!
Due to a meeting of the scientific committee of the incoming O’Bayes 2013 meeting (in Duke, December, more about this soon!), whose most members were attending this workshop, I missed the beginning of Alan Aggresti’s talk and could not catch up with the central problem he was addressing (the pianist on the street outside started pounding on his instrument as if intent to break it apart!). A pity as problems with contingency tables are certainly of interest to me… By the end of Alan’s talk, I wished someone would shoot the pianist playing outside (even though he was reasonably gifted) as I had gotten a major headache from his background noise. Following Noel Cressie’s talk proved just as difficult, although I could see his point in comparing very diverse predictors for big Data problems without much of a model structure and even less of a and I decided to call the day off, despite wishing to stay for Eduardo Gutiérrez-Pena’s talk on conjugate predictives and entropies which definitely interested me… Too bad really (blame the pianist!)


![\mathbb{E}^\pi\left[\mathbb{E}_\theta\{\log f(X|\theta)/ f(X|\theta_0)\}|x\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5E%5Cpi%5Cleft%5B%5Cmathbb%7BE%7D_%5Ctheta%5C%7B%5Clog+f%28X%7C%5Ctheta%29%2F+f%28X%7C%5Ctheta_0%29%5C%7D%7Cx%5Cright%5D%2C&bg=000000&fg=B0B0B0&s=0&c=20201002)

