Archive for matrix algebra
matrix multiplication [cover]
Posted in Books, pictures, Statistics, University life with tags algorithms, AlphaTensor, cover, deep learning, deep neural network, DeepMind, Google, London, matrix algebra, matrix multiplication, Monte Carlo algorithm, Nature, reinforcement learning, tensor, UK on December 15, 2022 by xi'an matrix multiplication algorithms by DeepMind. Although the gains on GPUs remain relatively modest, i.e. less than 10%. I am unsure how the algorithms can be recovered, given that AlphaTensor produces algorithms by the thousands for each matrix size.")
learning base R [book review]
Posted in Books, Kids, Statistics, University life with tags Black-Scholes formula, book review, Brownian motion, CHANCE, complex numbers, directory, Eratosthenes, introductory textbooks, loops, matrix algebra, probability distribution, R, R package, R studio, Rmarkdown, simulation, Squid Games on February 26, 2022 by xi'an This second edition of an introductory R book was sent to me by the author for a potential CHANCE book review. As there are many (many) books in the same spirit, the main question behind my reading it (in one go) was on the novelty it brings. The topics Learning Base R covers are
This second edition of an introductory R book was sent to me by the author for a potential CHANCE book review. As there are many (many) books in the same spirit, the main question behind my reading it (in one go) was on the novelty it brings. The topics Learning Base R covers are
- arithmetics with R
- data structures
- built-in and user-written R functions
- R utilities
- more data structures
- comparison and coercion
- lists and data frames
- resident R datasets
- R interface
- probability calculations in R
- R graphics
- R programming
- simulations
- statistical inference in R
- linear algebra
- use of R packages
within as many short chapters. The style is rather standard, that is, short paragraphs with mostly raw reproductions of line commands and their outcome. Sometimes a whole page long of code examples (if with comments). All in all I feel there are rather too few tables when compared with examples, at least for my own taste. The exercises are mostly short and, while they vary in depth, they show that the book is rather intended for students with some mathematical background (e.g., with a chapter on complex numbers and another one on linear algebra that do not seem immediately relevant for most intended readers). Or more than that, when considering one (of several) exercise (19.30) on the Black-Scholes process that mentions Brownian motion. Possibly less appealing for would-be statisticians.
I also wonder at the pedagogical choice of not including and involving more clearly graphical interfaces like R studio as students are usually not big fans of “old-style” [their wording not mine!] line command languages. For instance, the chapter on packages would have benefited from this perspective. Nothing on Rmarkdown either. Apparently nothing on handling big data, more advanced database manipulation, the related realistic dangers of memory freeze and compulsory reboot, the intricacies of managing different directories and earlier sessions, little on the urgency of avoiding loops (p.233) by vectorial programming, a paradoxically if function being introduced after ifelse, and again not that much on statistics (with density only occurring in exercises).The chapter on customising R graphics may possibly scare the intended reader when considering the all-in-one example of p.193! As we advance though the book, the more advanced examples often are fairly standard programming ones (found in other language manuals) like creating Fibonacci numbers, implementing Eratosthenes sieve, playing the Hanoi Tower game… (At least they remind me of examples read in the language manuals I read as a student.) The simulation chapter could have gone into the one (Chap. 19) on probability calculations, rather than superfluously redefining standard distributions. (Except when defining a random number as a uniformly random number (p.162).) This chapter also spends an unusual amount of space on linear congruencial pseudo-random generators, while missing to point out the trivia that the randu dataset mentioned twice earlier is actually an outcome from the infamous RANDU Fortran generator. The following section in that chapter is written in such a way that it may give the wrong impression that one can find the analytic solution from repeated Monte Carlo experiments and hence the error. Which is rarely the case, even in finite environments with rational expectations, as one usually does not know of which unit fraction the expectation should be a multiple of. (Remember the Squid Games paradox!) And no mention is made of the prescription of always returning an error estimate along with the numerical approximation. The statistics chapter is obviously more developed, with descriptive statistics, ecdf, but no bootrstap, a t.test curiously applied to the Michelson measurements of the speed of light (how could it be zero?!), ANOVA, regression handled via lm and glm, time series analysis by ARIMA models, which I hope will not be the sole exposure of readers to these concepts.
In conclusion, there is nothing critically wrong with this manual introducing R to newcomers and I would not mind having my undergraduate students reading it (rather than our shorter and home-made handout, polished along the years) before my first mathematical statistics lab. However I do not find it massively innovative in its presentation or choice of concept, even though the most advanced examples are not necessarily standard, and may not appeal to all categories of students.
[Disclaimer about potential self-plagiarism: this post or an edited version will eventually appear in my Book Review section in CHANCE.]
Statistical rethinking [book review]
Posted in Books, Kids, R, Statistics, University life with tags Amazon, Bayes theorem, Bayesian data analysis, Bayesian Essentials with R, book review, CHANCE, code, convergence diagnostics, E.T. Jaynes, generalised linear models, golem, maths, matrix algebra, MCMC algorithms, mixtures of distributions, Monte Carlo Statistical Methods, Prague, R, robots, STAN, statistical modelling, Statistical rethinking on April 6, 2016 by xi'an Statistical Rethinking: A Bayesian Course with Examples in R and Stan is a new book by Richard McElreath that CRC Press sent me for review in CHANCE. While the book was already discussed on Andrew’s blog three months ago, and [rightly so!] enthusiastically recommended by Rasmus Bååth on Amazon, here are the reasons why I am quite impressed by Statistical Rethinking!
Statistical Rethinking: A Bayesian Course with Examples in R and Stan is a new book by Richard McElreath that CRC Press sent me for review in CHANCE. While the book was already discussed on Andrew’s blog three months ago, and [rightly so!] enthusiastically recommended by Rasmus Bååth on Amazon, here are the reasons why I am quite impressed by Statistical Rethinking!
“Make no mistake: you will wreck Prague eventually.” (p.10)
While the book has a lot in common with Bayesian Data Analysis, from being in the same CRC series to adopting a pragmatic and weakly informative approach to Bayesian analysis, to supporting the use of STAN, it also nicely develops its own ecosystem and idiosyncrasies, with a noticeable Jaynesian bent. To start with, I like the highly personal style with clear attempts to make the concepts memorable for students by resorting to external concepts. The best example is the call to the myth of the golem in the first chapter, which McElreath uses as an warning for the use of statistical models (which almost are anagrams to golems!). Golems and models [and robots, another concept invented in Prague!] are man-made devices that strive to accomplish the goal set to them without heeding the consequences of their actions. This first chapter of Statistical Rethinking is setting the ground for the rest of the book and gets quite philosophical (albeit in a readable way!) as a result. In particular, there is a most coherent call against hypothesis testing, which by itself justifies the title of the book. Continue reading
the worst possible proof [X’ed]
Posted in Books, Kids, Statistics, University life with tags Bayesian Analysis, conjugate priors, introductory textbooks, linear model, matrix algebra, Pythagorean theorem, social sciences on July 18, 2015 by xi'an
Another surreal experience thanks to X validated! A user of the forum recently asked for an explanation of the above proof in Lynch’s (2007) book, Introduction to Applied Bayesian Statistics and Estimation for Social Scientists. No wonder this user was puzzled: the explanation makes no sense outside the univariate case… It is hard to fathom why on Earth the author would resort to this convoluted approach to conclude about the posterior conditional distribution being a normal centred at the least square estimate and with σ²X’X as precision matrix. Presumably, he has a poor opinion of the degree of matrix algebra numeracy of his readers [and thus should abstain from establishing the result]. As it seems unrealistic to postulate that the author is himself confused about matrix algebra, given his MSc in Statistics [the footnote ² seen above after “appropriately” acknowledges that “technically we cannot divide by” the matrix, but it goes on to suggest multiplying the numerator by the matrix
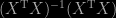
which does not make sense either, unless one introduces the trace tr(.) operator, presumably out of reach for most readers]. And this part of the explanation is unnecessarily confusing in that a basic matrix manipulation leads to the result. Or even simpler, a reference to Pythagoras’ theorem.
What are the distributions on the positive k-dimensional quadrant with parametrizable covariance matrix?
Posted in Books, pictures, Statistics, University life with tags correlation, covariance, covariance matrix, linear algebra, matrix algebra, multivariate analysis, positive quadrant on March 30, 2012 by xi'an This is the question I posted this morning on StackOverflow, following an exchange two days ago with a user who could not see why the linear transform of a log-normal vector X,
This is the question I posted this morning on StackOverflow, following an exchange two days ago with a user who could not see why the linear transform of a log-normal vector X,
Y = μ + Σ X
could lead to negative components in Y…. After searching a little while, I could not think of a joint distribution on the positive k-dimensional quadrant where I could specify the covariance matrix in advance. Except for a pedestrian construction of (x1,x2) where x1 would be an arbitrary Gamma variate [with a given variance] and x2 conditional on x1 would be a Gamma variate with parameters specified by the covariance matrix. Which does not extend nicely to larger dimensions.
