 A book to read most urgently if hoping to take an informed decision by 03 November! Written by a political scientist cum statistician, Ole Forsberg. (If you were thinking of another political scientist cum statistician, he wrote red state blue state a while ago! And is currently forecasting the outcome of the November election for The Economist.)
A book to read most urgently if hoping to take an informed decision by 03 November! Written by a political scientist cum statistician, Ole Forsberg. (If you were thinking of another political scientist cum statistician, he wrote red state blue state a while ago! And is currently forecasting the outcome of the November election for The Economist.)
“I believe [omitting educational level] was the main reason the [Brexit] polls were wrong.”
The first part of the book is about the statistical analysis of opinion polls (assuming their outcome is given, rather than designing them in the first place). And starting with the Scottish independence referendum of 2014. The first chapter covering the cartoon case of simple sampling from a population, with or without replacement, Bayes and non-Bayes. In somewhat too much detail imho given that this is an unrealistic description of poll outcomes. The second chapter expands to stratified sampling (with confusing title [Polling 399] and entry, since it discusses repeated polls that are not processed in said chapter). Mentioning the famous New York Times experiment where five groups of pollsters analysed the same data, making different decisions in adjusting the sample and identifying likely voters, and coming out with a range of five points in the percentage. Starting to get a wee bit more advanced when designing priors for the population proportions. But still studying a weighted average of the voting intentions for each category. Chapter three reaches the challenging task of combining polls, with a 2017 (South) Korea presidential election as an illustration, involving five polls. It includes a solution to handling older polls by proposing a simple linear regression against time. Chapter 4 sums up the challenges of real-life polling by examining the disastrous 2016 Brexit referendum in the UK. Exposing for instance the complicated biases resulting from polling by phone or on-line. The part that weights polling institutes according to quality does not provide any quantitative detail. (And also a weird averaging between the levels of “support for Brexit” and “maybe-support for Brexit”, see Fig. 4.5!) Concluding as quoted above that missing the educational stratification was the cause for missing the shock wave of referendum day is a possible explanation, but the massive difference in turnover between the age groups, itself possibly induced by the reassuring figures of the published polls and predictions, certainly played a role in missing the (terrible) outcome.
“The fabricated results conformed to Benford’s law on first digits, but failed to obey Benford’s law on second digits.” Wikipedia
The second part of this 200 page book is about election analysis, towards testing for fraud. Hence involving the ubiquitous Benford law. Although applied to the leading digit which I do not think should necessarily follow Benford law due to both the varying sizes and the non-uniform political inclinations of the voting districts (of which there are 39 for the 2009 presidential Afghan election illustration, although the book sticks at 34 (p.106)). My impression was that instead lesser digits should be tested. Chapter 4 actually supports the use of the generalised Benford distribution that accounts for differences in turnouts between the electoral districts. But it cannot come up with a real-life election where the B test points out a discrepancy (and hence a potential fraud). Concluding with the author’s doubt [repeated from his PhD thesis] that these Benford tests “are specious at best”, which makes me wonder why spending 20 pages on the topic. The following chapter thus considers other methods, checking for differential [i.e., not-at-random] invalidation by linear and generalised linear regression on the supporting rate in the district. Once again concluding at no evidence of such fraud when analysing the 2010 Côte d’Ivoire elections (that led to civil war). With an extension in Chapter 7 to an account for spatial correlation. The book concludes with an analysis of the Sri Lankan presidential elections between 1994 and 2019, with conclusions of significant differential invalidation in almost every election (even those not including Tamil provinces from the North).
R code is provided and discussed within the text. Some simple mathematical derivations are found, albeit with a huge dose of warnings (“math-heavy”, “harsh beauty”) and excuses (“feel free to skim”, “the math is entirely optional”). Often, one wonders at the relevance of said derivations for the intended audience and the overall purpose of the book. Nonetheless, it provides an interesting entry on (relatively simple) models applied to election data and could certainly be used as an original textbook on modelling aggregated count data, in particular as it should spark the interest of (some) students.
[Disclaimer about potential self-plagiarism: this post or an edited version will eventually appear in my Books Review section in CHANCE.]
 Infomocracy
Infomocracy


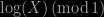 is uniform, which is the presentation given in the
is uniform, which is the presentation given in the  is
is 
{kind=link}