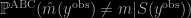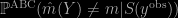An old riddle found on X validated asking for Monte Carlo resolution but originally given on Project Euler:
An old riddle found on X validated asking for Monte Carlo resolution but originally given on Project Euler:
A 30×30 grid of squares contains 30² fleas, initially one flea per square. When a bell is rung, each flea jumps to an adjacent square at random. What is the expected number of unoccupied squares after 50 bell rings, up to six decimal places?
The debate on X validated is whether or not a Monte Carlo resolution is feasible. Up to six decimals, certainly not. But with some lower precision, certainly. Here is a rather basic R code where the 50 steps are operated on the 900 squares, rather than the 900 fleas. This saves some time by avoiding empty squares.
xprmt=function(n=10,T=50){
mean=0
for (t in 1:n){
board=rep(1,900)
for (v in 1:T){
beard=rep(0,900)
if (board[1]>0){
poz=c(0,1,0,30)
ne=rmultinom(1,board[1],prob=(poz!=0))
beard[1+poz]=beard[1+poz]+ne}
#
for (i in (2:899)[board[-1][-899]>0]){
u=(i-1)%%30+1;v=(i-1)%/%30+1
poz=c(-(u>1),(u<30),-30*(v>1),30*(v<30))
ne=rmultinom(1,board[i],prob=(poz!=0))
beard[i+poz]=beard[i+poz]+ne}
#
if (board[900]>0){
poz=c(-1,0,-30,0)
ne=rmultinom(1,board[900],prob=(poz!=0))
beard[900+poz]=beard[900+poz]+ne}
board=beard}
mean=mean+sum(board==0)}
return(mean/n)}
The function returns an empirical average over n replications. With a presumably awkward approach to the borderline squares, since it involves adding zeros to keep the structure the same… Nonetheless, it produces an approximation that is rather close to the approximate expected value, in about 3mn on my laptop.
> exprmt(n=1e3) [1] 331.082 > 900/exp(1) [1] 331.0915
Further gains follow from considering only half of the squares, as there are two independent processes acting in parallel. I looked at an alternative and much faster approach using the stationary distribution, with the stationary being the Multinomial (450,(2/1740,3/1740…,4/1740,…,2/1740)) with probabilities proportional to 2 in the corner, 3 on the sides, and 4 in the inside. (The process, strictly speaking, has no stationary distribution, since it is periodic. But one can consider instead the subprocess indexed by even times.) This seems to be the case, though, when looking at the occupancy frequencies, after defining the stationary as:
inva=function(B=30){
return(c(2,rep(3,B-2),2,rep(c(3,
rep(4,B-2),3),B-2),2,rep(3,B-2),2))}
namely
> mn=0;n=1e8 #14 clock hours! > proz=rep(c(rep(c(0,1),15),rep(c(1,0),15)),15)*inva(30) > for (t in 1:n) + mn=mn+table(rmultinom(1,450,prob=rep(1,450)))[1:4] > mn=mn/n > mn[1]=mn[1]-450 > mn 0 1 2 3 166.11 164.92 82.56 27.71 > exprmt(n=1e6) #55 clock hours!! [1] 165.36 165.69 82.92 27.57
my original confusion being that the Poisson approximation had not yet taken over… (Of course, computing the first frequency for the stationary distribution does not require any simulation, since it is the sum of the complement probabilities to the power 450, i.e., 166.1069.)