 Our survey paper on Rao-Blackwellisation (and the first Robert&Roberts published paper!) just appeared on-line as part of the International Statistical Review mini-issue in honour of C.R. Rao on the occasion of his 100th birthday. (With an unfortunate omission of my affiliation with Warwick!). While the papers are unfortunately beyond a paywall, except for a few weeks!, the arXiv version is still available (and presumably with less typos!).
Our survey paper on Rao-Blackwellisation (and the first Robert&Roberts published paper!) just appeared on-line as part of the International Statistical Review mini-issue in honour of C.R. Rao on the occasion of his 100th birthday. (With an unfortunate omission of my affiliation with Warwick!). While the papers are unfortunately beyond a paywall, except for a few weeks!, the arXiv version is still available (and presumably with less typos!).
Archive for typos
RB4MCMC@ISR
Posted in Statistics with tags 100th birthday, arXiv, C.R. Rao, International Statistical Review, Rao-Blackwell theorem, Rao-Blackwellisation, typos, University of Warwick on August 18, 2021 by xi'anThe [errors in the] error of truth [book review]
Posted in Books, Statistics, University life with tags Abraham De Moivre, Académie des Sciences, book review, Carl Friedrich Gauss, central limit theorem, CHANCE, Edward Simpson, Enlightenment, eugenism, French Revolution, guillotine, Jakob Bernoulli, Karol Wojtyła, Law of Large Numbers, Margaret Thatcher, Marie Curie, Maximilien Robespierre, Ottoman Empire, OUP, Pierre Simon Laplace, Richard Price, Ronald Reagan, St Petersburg, The Bell Curve, Thomas Bayes, typos, Victorian society, Voltaire, wikipedia on August 10, 2021 by xi'an OUP sent me this book, The error of truth by Steven Osterling, for review. It is a story about the “astonishing” development of quantitative thinking in the past two centuries. Unfortunately, I found it to be one of the worst books I have read on the history of sciences…
OUP sent me this book, The error of truth by Steven Osterling, for review. It is a story about the “astonishing” development of quantitative thinking in the past two centuries. Unfortunately, I found it to be one of the worst books I have read on the history of sciences…
To start with the rather obvious part, I find the scholarship behind the book quite shoddy as the author continuously brings in items of historical tidbits to support his overall narrative and sometimes fills gaps on his own. It often feels like the material comes from Wikipedia, despite expressing a critical view of the on-line encyclopedia. The [long] quote below is presumably the most shocking historical blunder, as the terror era marks the climax of the French Revolution, rather than the last fight of the French monarchy. Robespierre was the head of the Jacobins, the most radical revolutionaries at the time, and one of the Assembly members who voted for the execution of Louis XIV, which took place before the Terror. And later started to eliminate his political opponents, until he found himself on the guillotine!
“The monarchy fought back with almost unimaginable savagery. They ordered French troops to carry out a bloody campaign in which many thousands of protesters were killed. Any peasant even remotely suspected of not supporting the government was brutally killed by the soldiers; many were shot at point-blank range. The crackdown’s most intense period was a horrific ten-month Reign of Terror (“la Terreur”) during which the government guillotined untold masses (some estimates are as high as 5,000) of its own citizens as a means to control them. One of the architects of the Reign of Terror was Maximilien Robespierre, a French nobleman and lifelong politician. He explained the government’s slaughter in unbelievable terms, as “justified terror . . . [and] an emanation of virtue” (quoted in Linton 2006). Slowly, however, over the next few years, the people gained control. In the end, many nobles, including King Louis XVI and his wife Marie-Antoinette, were themselves executed by guillotining”
Obviously, this absolute misinterpretation does not matter (very) much for the (hi)story of quantification (and uncertainty assessment), but it demonstrates a lack of expertise of the author. And sap whatever trust one could have in new details he brings to light (life?). As for instance when stating
“Bayes did a lot of his developmental work while tutoring students in local pubs. He was a respected teacher. Taking advantage of his immediate resources (in his circumstance, a billiard table), he taught his theorem to many.”
which does not sound very plausible. I never heard that Bayes had students or went to pubs or exposed his result to many before its posthumous publication… Or when Voltaire (who died in 1778) is considered as seventeenth-century precursor of the Enlightenment. Or when John Graunt, true member of the Royal Society, is given as a member of the Académie des Sciences. Or when Quetelet is presented as French and as a student of Laplace.
The maths explanations are also puzzling, from the law of large numbers illustrated by six observations, and wrongly expressed (p.54) as
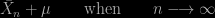
to the Saint-Petersbourg paradox being seen as inverse probability, to a botched description of the central limit theorem (p.59), including the meaningless equation (p.60)
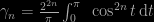
to de Moivre‘s theorem being given as Taylor’s expansion

and as his derivation of the concept of variance, to another botched depiction of the difference between Bayesian and frequentist statistics, incl. the usual horror

to independence being presented as a non-linear relation (p.111), to the conspicuous absence of Pythagoras in the regression chapter, to attributing to Gauss the concept of a probability density (when Simpson, Bayes, Laplace used it as well), to another highly confusing verbal explanation of densities, including a potential confusion between different representations of a distribution (Fig. 9.6) and the existence of distributions other than the Gaussian distribution, to another error in writing the Gaussian pdf (p.157),
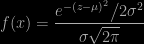
to yet another error in the item response probability (p.301), and.. to completely missing the distinction between the map and the territory, i.e., the probabilistic model and the real world (“Truth”), which may be the most important shortcoming of the book.
The style is somewhat heavy, with many repetitions about the greatness of the characters involved in the story, and some degree of license in bringing them within the narrative of the book. The historical determinism of this narrative is indeed strong, with a tendency to link characters more than they were, and to make them greater than life. Which is a usual drawback of such books, along with the profuse apologies for presenting a few mathematical formulas!
The overall presentation further has a Victorian and conservative flavour in its adoration of great names, an almost exclusive centering on Western Europe, a patriarchal tone (“It was common for them to assist their husbands in some way or another”, p.44; Marie Curie “agreed to the marriage, believing it would help her keep her laboratory position”, p.283), a defense of the empowerment allowed by the Industrial Revolution and of the positive sides of colonialism and of the Western expansion of the USA, including the invention of Coca Cola as a landmark in the march to Progress!, to the fall of the (communist) Eastern Block being attributed to Ronald Reagan, Karol Wojtyła, and Margaret Thatcher, to the Bell Curve being written by respected professors with solid scholarship, if controversial, to missing the Ottoman Enlightenment and being particularly disparaging about the Middle East, to dismissing Galton’s eugenism as a later year misguided enthusiasm (and side-stepping the issue of Pearson’s and Fisher’s eugenic views),
Another recurrent if minor problem is the poor recording of dates and years when introducing an event or a new character. And the quotes referring to the current edition or translation instead of the original year as, e.g., Bernoulli (1954). Or even better!, Bayes and Price (1963).
[Disclaimer about potential self-plagiarism: this post or an edited version will eventually appear in my Book Review section in CHANCE.]
right place, wrong version
Posted in Statistics with tags ABC, Approximate Bayesian computation, copyediting, HAL, Helvetica, Journal of the Royal Statistical Society, Royal Statistical Society, Series B, typos, Wasserstein distance on August 12, 2020 by xi'an
a computational approach to statistical learning [book review]
Posted in Books, R, Statistics, University life with tags book review, CHANCE, computational statistics, Conan Doyle, COVID-19, CRC Press, Eiffel Peak, Elements of Statistical Learning, linear model, misspecified model, PCA, prediction, Sherlock Holmes, significance stars, Statistical learning, the the, typos on April 15, 2020 by xi'an This book was sent to me by CRC Press for review for CHANCE. I read it over a few mornings while [confined] at home and found it much more computational than statistical. In the sense that the authors go quite thoroughly into the construction of standard learning procedures, including home-made R codes that obviously help in understanding the nitty-gritty of these procedures, what they call try and tell, but that the statistical meaning and uncertainty of these procedures remain barely touched by the book. This is not uncommon to the machine-learning literature where prediction error on the testing data often appears to be the final goal but this is not so traditionally statistical. The authors introduce their work as (a computational?) supplementary to Elements of Statistical Learning, although I would find it hard to either squeeze both books into one semester or dedicate two semesters on the topic, especially at the undergraduate level.
This book was sent to me by CRC Press for review for CHANCE. I read it over a few mornings while [confined] at home and found it much more computational than statistical. In the sense that the authors go quite thoroughly into the construction of standard learning procedures, including home-made R codes that obviously help in understanding the nitty-gritty of these procedures, what they call try and tell, but that the statistical meaning and uncertainty of these procedures remain barely touched by the book. This is not uncommon to the machine-learning literature where prediction error on the testing data often appears to be the final goal but this is not so traditionally statistical. The authors introduce their work as (a computational?) supplementary to Elements of Statistical Learning, although I would find it hard to either squeeze both books into one semester or dedicate two semesters on the topic, especially at the undergraduate level.
Each chapter includes an extended analysis of a specific dataset and this is an asset of the book. If sometimes over-reaching in selling the predictive power of the procedures. Printed extensive R scripts may prove tiresome in the long run, at least to me, but this may simply be a generational gap! And the learning models are mostly unidimensional, see eg the chapter on linear smoothers with imho a profusion of methods. (Could someone please explain the point of Figure 4.9 to me?) The chapter on neural networks has a fairly intuitive introduction that should reach fresh readers. Although meeting the handwritten digit data made me shift back to the late 1980’s, when my wife was working on automatic character recognition. But I found the visualisation of the learning weights for character classification hinting at their shape (p.254) most alluring!
Among the things I am missing when reading through this book, a life-line on the meaning of a statistical model beyond prediction, attention to misspecification, uncertainty and variability, especially when reaching outside the range of the learning data, and further especially when returning regression outputs with significance stars, discussions on the assessment tools like the distance used in the objective function (for instance lacking in scale invariance when adding errors on the regression coefficients) or the unprincipled multiplication of calibration parameters, some asymptotics, at least one remark on the information loss due to splitting the data into chunks, giving some (asymptotic) substance when using “consistent”, waiting for a single page 319 to see the “data quality issues” being mentioned. While the methodology is defended by algebraic and calculus arguments, there is very little on the probability side, which explains why the authors consider that the students need “be familiar with the concepts of expectation, bias and variance”. And only that. A few paragraphs on the Bayesian approach are doing more harm than well, especially with so little background in probability and statistics.
The book possibly contains the most unusual introduction to the linear model I can remember reading: Coefficients as derivatives… Followed by a very detailed coverage of matrix inversion and singular value decomposition. (Would not sound like the #1 priority were I to give such a course.)
The inevitable typo “the the” was found on page 37! A less common typo was Jensen’s inequality spelled as “Jenson’s inequality”. Both in the text (p.157) and in the index, followed by a repetition of the same formula in (6.8) and (6.9). A “stwart” (p.179) that made me search a while for this unknown verb. Another typo in the Nadaraya-Watson kernel regression, when the bandwidth h suddenly turns into n (and I had to check twice because of my poor eyesight!). An unusual use of partition where the sets in the partition are called partitions themselves. Similarly, fluctuating use of dots for products in dimension one, including a form of ⊗ for matricial product (in equation (8.25)) followed next page by the notation for the Hadamard product. I also suspect the matrix K in (8.68) is missing 1’s or am missing the point, since K is the number of kernels on the next page, just after a picture of the Eiffel Tower…) A surprising number of references for an undergraduate textbook, with authors sometimes cited with full name and sometimes cited with last name. And technical reports that do not belong to this level of books. Let me add the pedant remark that Conan Doyle wrote more novels “that do not include his character Sherlock Holmes” than novels which do include Sherlock.
[Disclaimer about potential self-plagiarism: this post or an edited version will eventually appear in my Books Review section in CHANCE.]
a glaring mistake
Posted in Statistics with tags Bayes factor, Bayesian hypothesis testing, Bayesian textbook, cross validated, Stack Exchange, The Bayesian Choice, typos on November 28, 2018 by xi'an Someone posted this question about Bayes factors in my book on Saturday morning and I could not believe the glaring typo pointed out there had gone through the centuries without anyone noticing! There should be no index 0 or 1 on the θ’s in either integral (or indices all over). I presume I made this typo when cutting & pasting from the previous formula (which addressed the case of two point null hypotheses), but I am quite chagrined that I sabotaged the definition of the Bayes factor for generations of readers of the Bayesian Choice. Apologies!!!
Someone posted this question about Bayes factors in my book on Saturday morning and I could not believe the glaring typo pointed out there had gone through the centuries without anyone noticing! There should be no index 0 or 1 on the θ’s in either integral (or indices all over). I presume I made this typo when cutting & pasting from the previous formula (which addressed the case of two point null hypotheses), but I am quite chagrined that I sabotaged the definition of the Bayes factor for generations of readers of the Bayesian Choice. Apologies!!!
