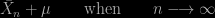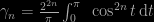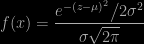[As I happened to be a reviewer of this book by Persi Diaconis and Brian Skyrms, I had the opportunity (and privilege!) to go through its earlier version. Here are the [edited] comments I sent back to PUP and the authors about this earlier version. All in all, a terrific book!!!]
 The historical introduction (“measurement”) of this book is most interesting, especially its analogy of chance with length. I would have appreciated a connection earlier than Cardano, like some of the Greek philosophers even though I gladly discovered there that Cardano was not only responsible for the closed form solutions to the third degree equation. I would also have liked to see more comments on the vexing issue of equiprobability: we all spend (if not waste) hours in the classroom explaining to (or arguing with) students why their solution is not correct. And they sometimes never get it! [And we sometimes get it wrong as well..!] Why is such a simple concept so hard to explicit? In short, but this is nothing but a personal choice, I would have made the chapter more conceptual and less chronologically historical.
The historical introduction (“measurement”) of this book is most interesting, especially its analogy of chance with length. I would have appreciated a connection earlier than Cardano, like some of the Greek philosophers even though I gladly discovered there that Cardano was not only responsible for the closed form solutions to the third degree equation. I would also have liked to see more comments on the vexing issue of equiprobability: we all spend (if not waste) hours in the classroom explaining to (or arguing with) students why their solution is not correct. And they sometimes never get it! [And we sometimes get it wrong as well..!] Why is such a simple concept so hard to explicit? In short, but this is nothing but a personal choice, I would have made the chapter more conceptual and less chronologically historical.
“Coherence is again a question of consistent evaluations of a betting arrangement that can be implemented in alternative ways.” (p.46)
The second chapter, about Frank Ramsey, is interesting, if only because it puts this “man of genius” back under the spotlight when he has all but been forgotten. (At least in my circles.) And for joining probability and utility together. And for postulating that probability can be derived from expectations rather than the opposite. Even though betting or gambling has a (negative) stigma in many cultures. At least gambling for money, since most of our actions involve some degree of betting. But not in a rational or reasoned manner. (Of course, this is not a mathematical but rather a psychological objection.) Further, the justification through betting is somewhat tautological in that it assumes probabilities are true probabilities from the start. For instance, the Dutch book example on p.39 produces a gain of .2 only if the probabilities are correct.
> gain=rep(0,1e4)
> for (t in 1:1e4){
+ p=rexp(3);p=p/sum(p)
+ gain[t]=(p[1]*(1-.6)+p[2]*(1-.2)+p[3]*(.9-1))/sum(p)}
> hist(gain)
As I made it clear at the BFF4 conference last Spring, I now realise I have never really adhered to the Dutch book argument. This may be why I find the chapter somewhat unbalanced with not enough written on utilities and too much on Dutch books.
“The force of accumulating evidence made it less and less plausible to hold that subjective probability is, in general, approximate psychology.” (p.55)
A chapter on “psychology” may come as a surprise, but I feel a posteriori that it is appropriate. Most of it is about the Allais paradox. Plus entries on Ellesberg’s distinction between risk and uncertainty, with only the former being quantifiable by “objective” probabilities. And on Tversky’s and Kahneman’s distinction between heuristics, and the framing effect, i.e., how the way propositions are expressed impacts the choice of decision makers. However, it is leaving me unclear about the conclusion that the fact that people behave irrationally should not prevent a reliance on utility theory. Unclear because when taking actions involving other actors their potentially irrational choices should also be taken into account. (This is mostly nitpicking.)
“This is Bernoulli’s swindle. Try to make it precise and it falls apart. The conditional probabilities go in different directions, the desired intervals are of different quantities, and the desired probabilities are different probabilities.” (p.66)
The next chapter (“frequency”) is about Bernoulli’s Law of Large numbers and the stabilisation of frequencies, with von Mises making it the basis of his approach to probability. And Birkhoff’s extension which is capital for the development of stochastic processes. And later for MCMC. I like the notions of “disreputable twin” (p.63) and “Bernoulli’s swindle” about the idea that “chance is frequency”. The authors call the identification of probabilities as limits of frequencies Bernoulli‘s swindle, because it cannot handle zero probability events. With a nice link with the testing fallacy of equating rejection of the null with acceptance of the alternative. And an interesting description as to how Venn perceived the fallacy but could not overcome it: “If Venn’s theory appears to be full of holes, it is to his credit that he saw them himself.” The description of von Mises’ Kollectiven [and the welcome intervention of Abraham Wald] clarifies my previous and partial understanding of the notion, although I am unsure it is that clear for all potential readers. I also appreciate the connection with the very notion of randomness which has not yet found I fear a satisfactory definition. This chapter asks more (interesting) questions than it brings answers (to those or others). But enough, this is a brilliant chapter!
“…a random variable, the notion that Kac found mysterious in early expositions of probability theory.” (p.87)
Chapter 5 (“mathematics”) is very important [from my perspective] in that it justifies the necessity to associate measure theory with probability if one wishes to evolve further than urns and dices. To entitle Kolmogorov to posit his axioms of probability. And to define properly conditional probabilities as random variables (as my third students fail to realise). I enjoyed very much reading this chapter, but it may prove difficult to read for readers with no or little background in measure (although some advanced mathematical details have vanished from the published version). Still, this chapter constitutes a strong argument for preserving measure theory courses in graduate programs. As an aside, I find it amazing that mathematicians (even Kac!) had not at first realised the connection between measure theory and probability (p.84), but maybe not so amazing given the difficulty many still have with the notion of conditional probability. (Now, I would have liked to see some description of Borel’s paradox when it is mentioned (p.89).
“Nothing hangs on a flat prior (…) Nothing hangs on a unique quantification of ignorance.” (p.115)
The following chapter (“inverse inference”) is about Thomas Bayes and his posthumous theorem, with an introduction setting the theorem at the centre of the Hume-Price-Bayes triangle. (It is nice that the authors include a picture of the original version of the essay, as the initial title is much more explicit than the published version!) A short coverage, in tune with the fact that Bayes only contributed a twenty-plus paper to the field. And to be logically followed by a second part [formerly another chapter] on Pierre-Simon Laplace, both parts focussing on the selection of prior distributions on the probability of a Binomial (coin tossing) distribution. Emerging into a discussion of the position of statistics within or even outside mathematics. (And the assertion that Fisher was the Einstein of Statistics on p.120 may be disputed by many readers!)
“So it is perfectly legitimate to use Bayes’ mathematics even if we believe that chance does not exist.” (p.124)
The seventh chapter is about Bruno de Finetti with his astounding representation of exchangeable sequences as being mixtures of iid sequences. Defining an implicit prior on the side. While the description sticks to binary events, it gets quickly more advanced with the notion of partial and Markov exchangeability. With the most interesting connection between those exchangeabilities and sufficiency. (I would however disagree with the statement that “Bayes was the father of parametric Bayesian analysis” [p.133] as this is extrapolating too much from the Essay.) My next remark may be non-sensical, but I would have welcomed an entry at the end of the chapter on cases where the exchangeability representation fails, for instance those cases when there is no sufficiency structure to exploit in the model. A bonus to the chapter is a description of Birkhoff’s ergodic theorem “as a generalisation of de Finetti” (p..134-136), plus half a dozen pages of appendices on more technical aspects of de Finetti’s theorem.
“We want random sequences to pass all tests of randomness, with tests being computationally implemented”. (p.151)
The eighth chapter (“algorithmic randomness”) comes (again!) as a surprise as it centres on the character of Per Martin-Löf who is little known in statistics circles. (The chapter starts with a picture of him with the iconic Oberwolfach sculpture in the background.) Martin-Löf’s work concentrates on the notion of randomness, in a mathematical rather than probabilistic sense, and on the algorithmic consequences. I like very much the section on random generators. Including a mention of our old friend RANDU, the 16 planes random generator! This chapter connects with Chapter 4 since von Mises also attempted to define a random sequence. To the point it feels slightly repetitive (for instance Jean Ville is mentioned in rather similar terms in both chapters). Martin-Löf’s central notion is computability, which forces us to visit Turing’s machine. And its role in the undecidability of some logical statements. And Church’s recursive functions. (With a link not exploited here to the notion of probabilistic programming, where one language is actually named Church, after Alonzo Church.) Back to Martin-Löf, (I do not see how his test for randomness can be implemented on a real machine as the whole test requires going through the entire sequence: since this notion connects with von Mises’ Kollektivs, I am missing the point!) And then Kolmororov is brought back with his own notion of complexity (which is also Chaitin’s and Solomonov’s). Overall this is a pretty hard chapter both because of the notions it introduces and because I do not feel it is completely conclusive about the notion(s) of randomness. A side remark about casino hustlers and their “exploitation” of weak random generators: I believe Jeff Rosenthal has a similar if maybe simpler story in his book about Canadian lotteries.
“Does quantum mechanics need a different notion of probability? We think not.” (p.180)
 The penultimate chapter is about Boltzmann and the notion of “physical chance”. Or statistical physics. A story that involves Zermelo and Poincaré, And Gibbs, Maxwell and the Ehrenfests. The discussion focus on the definition of probability in a thermodynamic setting, opposing time frequencies to space frequencies. Which requires ergodicity and hence Birkhoff [no surprise, this is about ergodicity!] as well as von Neumann. This reaches a point where conjectures in the theory are yet open. What I always (if presumably naïvely) find fascinating in this topic is the fact that ergodicity operates without requiring randomness. Dynamical systems can enjoy ergodic theorem, while being completely deterministic.) This chapter also discusses quantum mechanics, which main tenet requires probability. Which needs to be defined, from a frequency or a subjective perspective. And the Bernoulli shift that brings us back to random generators. The authors briefly mention the Einstein-Podolsky-Rosen paradox, which sounds more metaphysical than mathematical in my opinion, although they get to great details to explain Bell’s conclusion that quantum theory leads to a mathematical impossibility (but they lost me along the way). Except that we “are left with quantum probabilities” (p.183). And the chapter leaves me still uncertain as to why statistical mechanics carries the label statistical. As it does not seem to involve inference at all.
The penultimate chapter is about Boltzmann and the notion of “physical chance”. Or statistical physics. A story that involves Zermelo and Poincaré, And Gibbs, Maxwell and the Ehrenfests. The discussion focus on the definition of probability in a thermodynamic setting, opposing time frequencies to space frequencies. Which requires ergodicity and hence Birkhoff [no surprise, this is about ergodicity!] as well as von Neumann. This reaches a point where conjectures in the theory are yet open. What I always (if presumably naïvely) find fascinating in this topic is the fact that ergodicity operates without requiring randomness. Dynamical systems can enjoy ergodic theorem, while being completely deterministic.) This chapter also discusses quantum mechanics, which main tenet requires probability. Which needs to be defined, from a frequency or a subjective perspective. And the Bernoulli shift that brings us back to random generators. The authors briefly mention the Einstein-Podolsky-Rosen paradox, which sounds more metaphysical than mathematical in my opinion, although they get to great details to explain Bell’s conclusion that quantum theory leads to a mathematical impossibility (but they lost me along the way). Except that we “are left with quantum probabilities” (p.183). And the chapter leaves me still uncertain as to why statistical mechanics carries the label statistical. As it does not seem to involve inference at all.
“If you don’t like calling these ignorance priors on the ground that they may be sharply peaked, call them nondogmatic priors or skeptical priors, because these priors are quite in the spirit of ancient skepticism.” (p.199)
And then the last chapter (“induction”) brings us back to Hume and the 18th Century, where somehow “everything” [including statistics] started! Except that Hume’s strong scepticism (or skepticism) makes induction seemingly impossible. (A perspective with which I agree to some extent, if not to Keynes’ extreme version, when considering for instance financial time series as stationary. And a reason why I do not see the criticisms contained in the Black Swan as pertinent because they savage normality while accepting stationarity.) The chapter rediscusses Bayes’ and Laplace’s contributions to inference as well, challenging Hume’s conclusion of the impossibility to finer. Even though the representation of ignorance is not unique (p.199). And the authors call again for de Finetti’s representation theorem as bypassing the issue of whether or not there is such a thing as chance. And escaping inductive scepticism. (The section about Goodman’s grue hypothesis is somewhat distracting, maybe because I have always found it quite artificial and based on a linguistic pun rather than a logical contradiction.) The part about (Richard) Jeffrey is quite new to me but ends up quite abruptly! Similarly about Popper and his exclusion of induction. From this chapter, I appreciated very much the section on skeptical priors and its analysis from a meta-probabilist perspective.
There is no conclusion to the book, but to end up with a chapter on induction seems quite appropriate. (But there is an appendix as a probability tutorial, mentioning Monte Carlo resolutions. Plus notes on all chapters. And a commented bibliography.) Definitely recommended!
[Disclaimer about potential self-plagiarism: this post or an edited version will eventually appear in my Books Review section in CHANCE. As appropriate for a book about Chance!]
 This “history of a revolutionary game of chance” is the latest book by Stephen Stigler and is indeed of an historical nature, following the French Lottery from its inception as Loterie royale in 1758 to the Loterie Nationale in 1836 (with the intermediate names of Loterie de France, Loterie Nationale, Loterie impériale, Loterie royale reflecting the agitated history of the turn of that Century!).
This “history of a revolutionary game of chance” is the latest book by Stephen Stigler and is indeed of an historical nature, following the French Lottery from its inception as Loterie royale in 1758 to the Loterie Nationale in 1836 (with the intermediate names of Loterie de France, Loterie Nationale, Loterie impériale, Loterie royale reflecting the agitated history of the turn of that Century!).