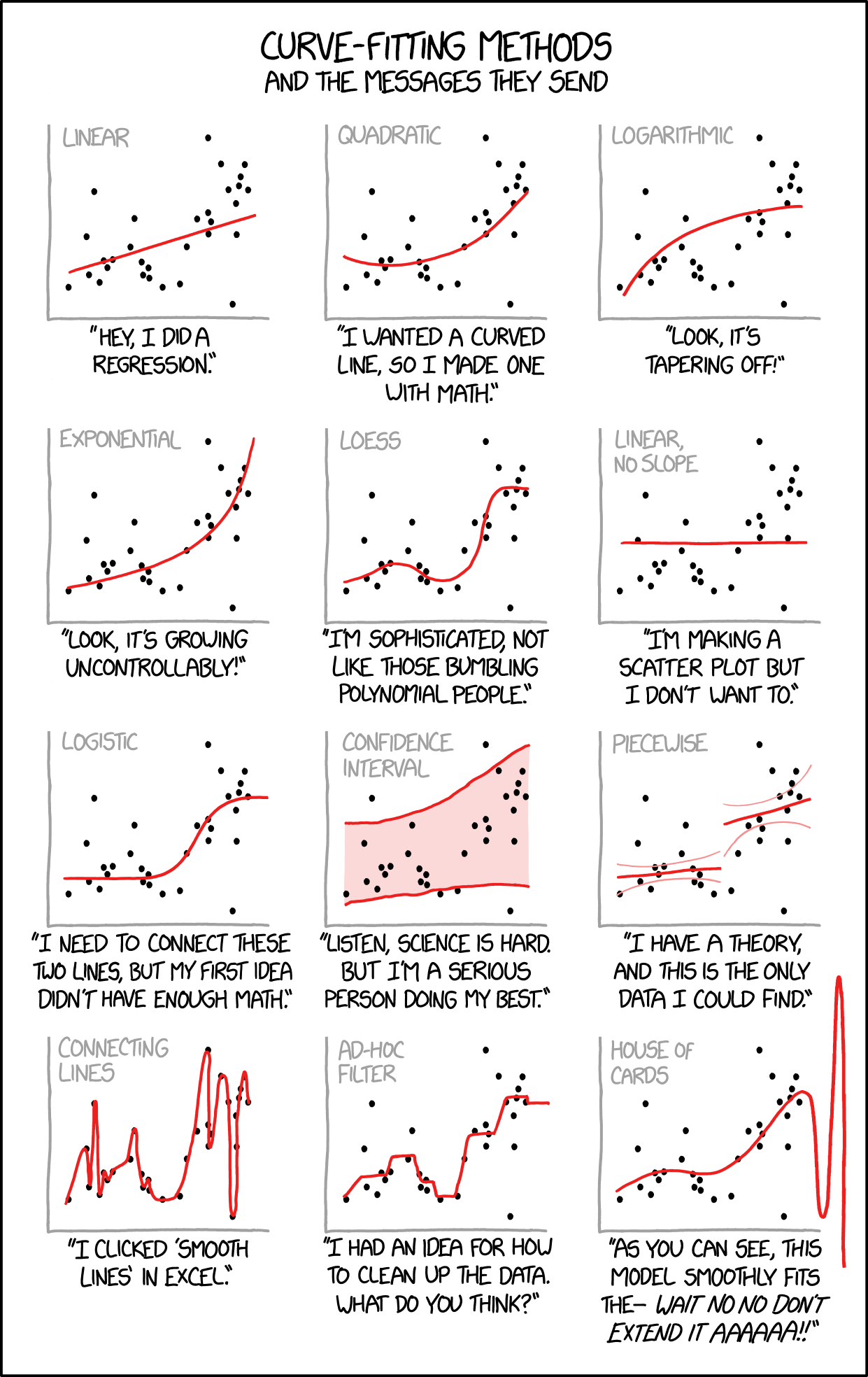
Archive for curve estimation
curve fittings [xkcd]
Posted in Books, Kids with tags curve estimation, extrapolation, graphics, LOESS, overfitting, splines, xkcd on November 4, 2018 by xi'an
workshop a Padova (finale)
Posted in pictures, Running, Statistics, Travel, University life, Wines with tags Bayesian model choice, Bayesian non-parametrics, credible set, curve estimation, hammerhead shark, Italia, Padova, risotto, Valpolicella on March 24, 2013 by xi'an
The third day of this rich Padova workshop was actually a half-day which, thanks to a talk cancellation, I managed to attend completely before flying back to Paris. The first talk by Matteo Botai was about the appeal of using quantile regression, as opposed to regular (or mean) regression. The talk was highly pedagogical and enthusiastic, hence enjoyable!, but I did not really buy the argument: if one starts modelling more than the conditional mean, the whole conditional distribution should be the target of the inference, rather than an arbitrary collection of quantiles, esp. if those are estimated marginaly and not jointly. There could be realistic exceptions, for instance legit 95% bounds/quantiles in medical trials, but they are certainly most rare (as exceptions should be!). This talk however led me to ponder about a possible connection with the g-and-k quantile distributions (whose dedicated monograph I did not really appreciate!) even though I had no satisfactory answer by the end of the talk. The second talk by Eva Cantoni dealt with a fishery problem—an ecological model close to my interests—that had nice hierarchical features and [of course] a possible Bayesian analysis of the random effects. This was not the path followed though and the likelihood analysis had to rely on bootstrap and other approximations. The motivation was provided by the very recent move of the hammerhead shark (among several species of shark) to the endangered species list and the data came from reported catches by commercial fishermen vessels. I have always wondered about the reliability of such data, unless there is a researcher on-board the vessel. Indeed, while the commercial catches are presumably checked upon arrival to comply with the quotas (at least in European waters), unintentional catches are presumably thrown away on the spot (maybe not since this is high quality flesh) and not at a time when careful statistics can be saved…
Actually, the whole fishing concept eludes me, even though I can see the commercial side of it: this is the only large-scale remainder of the early hunter-gatherer society and there is no ethical reason it should persist (well, other than feeding coastal populations that rely solely on fish catches, and even then…). The last two centuries have provided many instances of species extinction resulting from unlimited commercial fishing, but fishing is still going on… End of the parenthesis.
The last talk was by Aad van der Vaart, on non-parametric credible sets, i.e. credible sets on curves. Most of the talk was dedicated to the explanation of why there was an issue with those credible sets, that is, why they could be incredibly slow in catching the true curve and in shedding away the impact of the prior. This was most interesting, obviously, if ultimately not that surprising: the prior brings an amount of information that is infinitely larger than the one carried by a finite sample. The last part of the talk showed that the resolution of the difficulty was in selecting priors that avoid over-smoothing (although this depends on an unknown smoothness quantity as well). I liked very much this soft entry to the problem as it showed that all is not that rosy with the Bayesian non-parametric approach, whose foci on asymptotics or computation generally occult this finite sample issue.
Overall, I enjoyed very very much those three days in Padova, from the pleasant feeling of the old city and of the local food (best risottos in the past six months!, and a very decent Valpolicella as well) to the great company of old and new friends—making plans for a model choice brainstorming week in Paris in June—and to the new entries on Bayesian modelling and in particular Bayesian model choice I gathered from the talks. I am thus grateful to my friends Laura Ventura and Walter Racugno for their enormous investment in organising this workshop and in making it such a profitable and rich time. Grazie mille!
