
While simulating from a mixture of standard densities is relatively straightforward, when the component densities are easily simulated, to the point that many simulation methods exploit an intermediary mixture construction to speed up the production of pseudo-random samples from more challenging distributions (see Devroye, 1986), things get surprisingly more complicated when the mixture weights can take negative values. For instance, the naïve solution consisting in first simulating from the associated mixture of positive weight components
and then using an accept-reject step may prove highly inefficient since the overall probability of acceptance
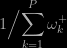
is the inverse of the sum of the positive weights and hence can be arbitrarily close to zero. The intuition for such inefficiency is that simulating from the positive weight components need not produce values within regions of high probability for the actual distribution

since its negative weight components may remove most of the mass under the positive weight components. In other words, the negative weight components do not have a natural latent variable interpretation and the resulting mixture can be anything, as the above graph testifies.
 Julien Stoehr (Paris Dauphine) and I started investigating this interesting challenge when the Master students who had been exposed to said challenge could not dent it in any meaningful way. We have now arXived a specific algorithm that proves superior to the naïve accept-reject algorithm, but also to the numerical cdf inversion (which happens to be available in this setting). Compared with the naïve version, we construct an alternative accept-reject scheme based on pairing positive and negative components as well as possible, partitioning the real line, and finding tighter upper and lower bounds on positive and negative components, respectively, towards yielding a higher acceptance rate on average. Designing a random generator of signed mixtures with enough variability and representativity proved a challenge in itself!
Julien Stoehr (Paris Dauphine) and I started investigating this interesting challenge when the Master students who had been exposed to said challenge could not dent it in any meaningful way. We have now arXived a specific algorithm that proves superior to the naïve accept-reject algorithm, but also to the numerical cdf inversion (which happens to be available in this setting). Compared with the naïve version, we construct an alternative accept-reject scheme based on pairing positive and negative components as well as possible, partitioning the real line, and finding tighter upper and lower bounds on positive and negative components, respectively, towards yielding a higher acceptance rate on average. Designing a random generator of signed mixtures with enough variability and representativity proved a challenge in itself!





