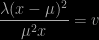While reading Boos and Hugues-Olivier’s 1998 American Statistician paper on the applications of Basu’s theorem I can across the notion of Monte Carlo swindles. Where a reduced variance can be achieved without the corresponding increase in Monte Carlo budget. For instance, approximating the variance of the median statistic Μ for a Normal location family can be sped up by considering that
While reading Boos and Hugues-Olivier’s 1998 American Statistician paper on the applications of Basu’s theorem I can across the notion of Monte Carlo swindles. Where a reduced variance can be achieved without the corresponding increase in Monte Carlo budget. For instance, approximating the variance of the median statistic Μ for a Normal location family can be sped up by considering that
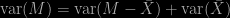
by Basu’s theorem. However, when reading the originating 1973 paper by Gross (although the notion is presumably due to Tukey), the argument boils down to Rao-Blackwellisation (without the Rao-Blackwell theorem being mentioned). The related 1985 American Statistician paper by Johnstone and Velleman exploits a latent variable representation. It also makes the connection with the control variate approach, noticing the appeal of using the score function as a (standard) control and (unusual) swindle, since its expectation is zero. I am surprised at uncovering this notion only now… Possibly because the method only applies in special settings.
A side remark from the same 1998 paper, namely that the enticing decomposition
![\mathbb E[(X/Y)^k] = \mathbb E[X^k] \big/ \mathbb E[Y^k]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%28X%2FY%29%5Ek%5D+%3D+%5Cmathbb+E%5BX%5Ek%5D+%5Cbig%2F+%5Cmathbb+E%5BY%5Ek%5D&bg=000000&fg=B0B0B0&s=0&c=20201002)
when X/Y and Y are independent, should be kept out of reach from my undergraduates at all costs, as they would quickly get rid of the assumption!!!
 When preparing my
When preparing my