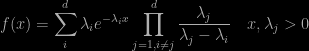Probabilistic numerics: Computation as machine learning is a 2022 book by Philipp Henning, Michael Osborne, and Hans Kersting that was sent to me by CUP (upon my request and almost free of charge, as I had to pay custom charges, thanks to Brexit!). With the important message of bringing statistical tools to numerics. I remember Persi Diaconis calling for (such) actions in the 1980’s (and even reading a paper of his on the topic along with George Casella in Ithaca while waiting for his car to get serviced!).
Probabilistic numerics: Computation as machine learning is a 2022 book by Philipp Henning, Michael Osborne, and Hans Kersting that was sent to me by CUP (upon my request and almost free of charge, as I had to pay custom charges, thanks to Brexit!). With the important message of bringing statistical tools to numerics. I remember Persi Diaconis calling for (such) actions in the 1980’s (and even reading a paper of his on the topic along with George Casella in Ithaca while waiting for his car to get serviced!).
From a purely aesthetic view point, the book reads well, offers a beautiful cover and sells for a quite reasonable price for an academic book. Plus it is associated with a website containing draft version of the book. Code, links to courses, research, conferences are also available there. Just a side remark that it enjoys very wide margins that may have encouraged an inflation of footnotes (but also exercises). Except when formulas get in the way (as e.g. on p.40).
The figure below is an excerpt from the introduction that sets the scene of probabilistic numerics involving algorithms as agents, gathering data and making decisions, with an obvious analogy with standard Bayesian decision theory. Modelling uncertainty missing from the picture (if not from the book, as explained later by the authors as an argument against attaching the label Bayesian to the field). Also referring to Henri Poincaré for the origination of the prior vs posterior uncertainty about a mathematical quantity. Followed by early works from the Russian school of probability, somewhat ignored until the machine-learning revolution and a 2012 NIPS workshop organised by the authors. (I participated to a follow-up workshop at NIPS 2015.)
In this nicely written section, I have an objection to the authors’ argument that a frequentist, as opposed to a Bayesian, “has the loss function in mind from the outset” (p.9), since the loss function is logically inseparable from the prior and considered from the onset. I also like very much the conclusion to that introduction, namely that the main messages (from the book) are that (verbatim)
- classical methods are probabilist (p.10)
- numerical methods are autonomous agents (p.11)
- numerics should not be random (if not a rejection of the concept of Monte Carlo methods, p.1, but probabilistic numerics being opposed to stochastic numerics, p.67)
- numerics must report calibrated uncertainty (p.12)
- imprecise computation is to be embraced (p.12)
- probabilistic numerics consolidates numerical computation and statistical inference (p.13)
- probabilistic numerical algorithms are already adding value (p.13)
- pipelines of computation demand harmonisation
“Is it still reasonable to labour under computational constraints conceived in the 1940s?” (p.113)
“rather than being equally good for any number of dimensions, Monte Carlo is perhaps better thought of as being equally bad” (p.110)
Chapter I is a 40p infodump (!) on mathematical concepts needed for the following parts. Chapter II is about integration, opposing again PN and Monte Carlo (with strange remark that MCMC does not achieve √N convergence rate, p.72). In the sense that the later is frequentist in that it does not use a prior [unless considering a limiting improper version as in Section 12.2, an intriguing concept in this setup as I wonder whether or not improper priors can at all be contemplated] on the object of interest and hence that the stochasticity does not reflect uncertainty but rather the impact of the simulated sample. Advocating Bayesian quadrature (with some weird convergence graphs exhibiting a high variability with the number of iterations that apparently is not discussed) and bringing in the fascinating perspective of model choice in that framework (leading to compute a posterior probability for each model!). Being evidently biased towards Monte Carlo, I find the opposition in Chapter 12 unnecessarily antagonistic, while presenting Monte Carlo methods as a form of minimax solution, the more because quasi-Monte Carlo methods are hardly discussed (or dismissed). As illustrated by the following picture (p.115) and the above quotes. (And I won’t even go into the absurdity of §12.3 trashing pseudo-random generators as “painfully dumb”.)

Chapter III is a sort of dual of Chapter II for linear algebra numerics, primarily solving linear equations by Gaussian solvers, which introduces new concepts like Krylov sequences, although it sounds quite specific (for an outsider like me). Chapters IV and V deal with the more ambitious prospect of optimisation. Reconsidering classics and expanding into Bayesian optimisation, using Gaussian process priors and defining specific loss functions. Bringing in a strong link with machine learning tools and goals. [citation typo on p.277]. Chapter VII addresses the resolution of ODEs by a Bayesian state space model representation and (again!) Gaussian processes. Reaching to mentioning inverse problems and offering a short finale on prospective steps for interested readers.
[Disclaimer about potential self-plagiarism: this post or an edited version will eventually appear in my Books Review section in CHANCE.]
 The next One World ABC seminar is taking place (on-line, requiring pre-registration) on Thursday 21 March, 9:00am UK time, with Desi Ivanova (University of Oxford), speaking about Step-DAD: Semi-Amortized Policy-Based Bayesian Experimental Design:
The next One World ABC seminar is taking place (on-line, requiring pre-registration) on Thursday 21 March, 9:00am UK time, with Desi Ivanova (University of Oxford), speaking about Step-DAD: Semi-Amortized Policy-Based Bayesian Experimental Design: We have
We have