 An interesting case on X validated of someone puzzled by the simulation (and variance) of the random variable 1/X when being able to simulate X. And being surprised at the variance of the ratio being way larger than the variances of both numerator and denominator.
An interesting case on X validated of someone puzzled by the simulation (and variance) of the random variable 1/X when being able to simulate X. And being surprised at the variance of the ratio being way larger than the variances of both numerator and denominator.
Archive for unconscious statistician
1 / duh?!
Posted in Books, R, Statistics, University life with tags cross validated, gamma distribution, inverse Gamma distribution, Monte Carlo, Moschopoulos distribution, simulation, teaching, unconscious statistician on September 28, 2021 by xi'aninverse Gaussian trick [or treat?]
Posted in Books, Kids, R, Statistics, University life with tags chi-square density, cumulant generating function, exam, exponential family, Fortran, George Casella, inverse Gaussian distribution, χ² distribution, JASA, mid-term exams, PRNG, pseudo-random generator, The American Statistician, unconscious statistician, Université Paris Dauphine on October 29, 2020 by xi'an When preparing my mid-term exam for my undergrad mathematical statistics course, I wanted to use the inverse Gaussian distribution IG(μ,λ) as an example of exponential family and include a random generator question. As shown above by a Fortran computer code from Michael, Schucany and Haas, a simple version can be based on simulating a χ²(1) variate and solving in x the following second degree polynomial equation
When preparing my mid-term exam for my undergrad mathematical statistics course, I wanted to use the inverse Gaussian distribution IG(μ,λ) as an example of exponential family and include a random generator question. As shown above by a Fortran computer code from Michael, Schucany and Haas, a simple version can be based on simulating a χ²(1) variate and solving in x the following second degree polynomial equation
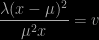
since the left-hand side transform is distributed as a χ²(1) random variable. The smallest root x¹, less than μ, is then chosen with probability μ/(μ+x¹) and the largest one, x²=μ²/x¹ with probability x¹/(μ+x¹). A relatively easy question then, except when one considers asking for the proof of the χ²(1) result, which proved itself to be a harder cookie than expected! The paper usually referred to for the result, Schuster (1968), is quite cryptic on the matter, essentially stating that the above can be expressed as the (bijective) transform of Y=min(X,μ²/X) and that V~χ²(1) follows immediately. I eventually worked out a proof by the “law of the unconscious statistician” [a name I do not find particularly amusing!], but did not include the question in the exam. But I found it fairly interesting that the inverse Gaussian can be generating by “inverting” the above equation, i.e. going from a (squared) Gaussian variate V to the inverse Gaussian variate X. (Even though the name stems from the two cumulant generating functions being inverses of one another.)
Probability and Bayesian modeling [book review]
Posted in Books, Kids, R, Statistics, University life with tags baseball data, book review, CRC Press, Cross Validation, deviance information criterion, DIC, dplyr, Francis Galton, JAGS, LaTeX, measure theory, Poisson distribution, Roger Federer, sub-two-hours marathon, subjective probability, the the, unconscious statistician, weakly informative prior on March 26, 2020 by xi'an Probability and Bayesian modeling is a textbook by Jim Albert [whose reply is included at the end of this entry] and Jingchen Hu that CRC Press sent me for review in CHANCE. (The book is also freely available in bookdown format.) The level of the textbook is definitely most introductory as it dedicates its first half on probability concepts (with no measure theory involved), meaning mostly focusing on counting and finite sample space models. The second half moves to Bayesian inference(s) with a strong reliance on JAGS for the processing of more realistic models. And R vignettes for the simplest cases (where I discovered R commands I ignored, like dplyr::mutate()!).
Probability and Bayesian modeling is a textbook by Jim Albert [whose reply is included at the end of this entry] and Jingchen Hu that CRC Press sent me for review in CHANCE. (The book is also freely available in bookdown format.) The level of the textbook is definitely most introductory as it dedicates its first half on probability concepts (with no measure theory involved), meaning mostly focusing on counting and finite sample space models. The second half moves to Bayesian inference(s) with a strong reliance on JAGS for the processing of more realistic models. And R vignettes for the simplest cases (where I discovered R commands I ignored, like dplyr::mutate()!).
As a preliminary warning about my biases, I am always reserved at mixing introductions to probability theory and to (Bayesian) statistics in the same book, as I feel they should be separated to avoid confusion. As for instance between histograms and densities, or between (theoretical) expectation and (empirical) mean. I therefore fail to relate to the pace and tone adopted in the book which, in my opinion, seems to dally on overly simple examples [far too often concerned with food or baseball] while skipping over the concepts and background theory. For instance, introducing the concept of subjective probability as early as page 6 is laudable but I doubt it will engage fresh readers when describing it as a measurement of one’s “belief about the truth of an event”, then stressing that “make any kind of measurement, one needs a tool like a scale or ruler”. Overall, I have no particularly focused criticisms on the probability part except for the discrete vs continuous imbalance. (With the Poisson distribution not covered in the Discrete Distributions chapter. And the “bell curve” making a weird and unrigorous appearance there.) Galton’s board (no mention found of quincunx) could have been better exploited towards the physical definition of a prior, following Steve Stiegler’s analysis, by adding a second level. Or turned into an R coding exercise. In the continuous distributions chapter, I would have seen the cdf coming first to the pdf, rather than the opposite. And disliked the notion that a Normal distribution was supported by an histogram of (marathon) running times, i.e. values lower bounded by 122 (at the moment). Or later (in Chapter 8) for Roger Federer’s serving times. Incidentally, a fun typo on p.191, at least fun for LaTeX users, as

with an extra space between `\’ and `mid’! (I also noticed several occurrences of the unvoidable “the the” typo in the last chapters.) The simulation from a bivariate Normal distribution hidden behind a customised R function sim_binom() when it could have been easily described as a two-stage hierarchy. And no comment on the fact that a sample from Y-1.5X could be directly derived from the joint sample. (Too unconscious a statistician?)
When moving to Bayesian inference, a large section is spent on very simple models like estimating a proportion or a mean, covering both discrete and continuous priors. And strongly focusing on conjugate priors despite giving warnings that they do not necessarily reflect prior information or prior belief. With some debatable recommendation for “large” prior variances as weakly informative or (worse) for Exp(1) as a reference prior for sample precision in the linear model (p.415). But also covering Bayesian model checking either via prior predictive (hence Bayes factors) or posterior predictive (with no mention of using the data twice). A very marginalia in introducing a sufficient statistic for the Normal model. In the Normal model checking section, an estimate of the posterior density of the mean is used without (apparent) explanation.
“It is interesting to note the strong negative correlation in these parameters. If one assigned informative independent priors on and , these prior beliefs would be counter to the correlation between the two parameters observed in the data.”
For the same reasons of having to cut on mathematical validation and rigour, Chapter 9 on MCMC is not explaining why MCMC algorithms are converging outside of the finite state space case. The proposal in the algorithmic representation is chosen as a Uniform one, since larger dimension problems are handled by either Gibbs or JAGS. The recommendations about running MCMC do not include how many iterations one “should” run (or other common queries on Stack eXchange), albeit they do include the sensible running multiple chains and comparing simulated predictive samples with the actual data as a model check. However, the MCMC chapter very quickly and inevitably turns into commented JAGS code. Which I presume would require more from the students than just reading the available code. Like JAGS manual. Chapter 10 is mostly a series of examples of Bayesian hierarchical modeling, with illustrations of the shrinkage effect like the one on the book cover. Chapter 11 covers simple linear regression with some mentions of weakly informative priors, although in a BUGS spirit of using large [enough?!] variances: “If one has little information about the location of a regression parameter, then the choice of the prior guess is not that important and one chooses a large value for the prior standard deviation . So the regression intercept and slope are each assigned a Normal prior with a mean of 0 and standard deviation equal to the large value of 100.” (p.415). Regardless of the scale of y? Standardisation is covered later in the chapter (with the use of the R function scale()) as part of constructing more informative priors, although this sounds more like data-dependent priors to me in the sense that the scale and location are summarily estimated by empirical means from the data. The above quote also strikes me as potentially confusing to the students, as it does not spell at all how to design a joint distribution on the linear regression coefficients that translate the concentration of these coefficients along y̅=β⁰+β¹x̄. Chapter 12 expands the setting to multiple regression and generalised linear models, mostly consisting of examples. It however suggests using cross-validation for model checking and then advocates DIC (deviance information criterion) as “to approximate a model’s out-of-sample predictive performance” (p.463). If only because it is covered in JAGS, the definition of the criterion being relegated to the last page of the book. Chapter 13 concludes with two case studies, the (often used) Federalist Papers analysis and a baseball career hierarchical model. Which may sound far-reaching considering the modest prerequisites the book started with.
In conclusion of this rambling [lazy Sunday] review, this is not a textbook I would have the opportunity to use in Paris-Dauphine but I can easily conceive its adoption for students with limited maths exposure. As such it offers a decent entry to the use of Bayesian modelling, supported by a specific software (JAGS), and rightly stresses the call to model checking and comparison with pseudo-observations. Provided the course is reinforced with a fair amount of computer labs and projects, the book can indeed achieve to properly introduce students to Bayesian thinking. Hopefully leading them to seek more advanced courses on the topic.
Update: Jim Albert sent me the following precisions after this review got on-line:
Thanks for your review of our recent book. We had a particular audience in mind, specifically undergraduate American students with some calculus background who are taking their first course in probability and statistics. The traditional approach (which I took many years ago) teaches some probability one semester and then traditional inference (focusing on unbiasedness, sampling distributions, tests and confidence intervals) in the second semester. There didn’t appear to be any Bayesian books at that calculus-based undergraduate level and that motivated the writing of this book. Anyway, I think your comments were certainly fair and we’ve already made some additions to our errata list based on your comments.
[Disclaimer about potential self-plagiarism: this post or an edited version will eventually appear in my Books Review section in CHANCE. As appropriate for a book about Chance!]
