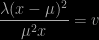Last morning at the neuroscience workshop Jean-François Cardoso presented independent component analysis though a highly pedagogical and enjoyable tutorial that stressed the geometric meaning of the approach, summarised by the notion that the (ICA) decomposition
Last morning at the neuroscience workshop Jean-François Cardoso presented independent component analysis though a highly pedagogical and enjoyable tutorial that stressed the geometric meaning of the approach, summarised by the notion that the (ICA) decomposition
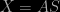
of the data X seeks both independence between the columns of S and non-Gaussianity. That is, getting as away from Gaussianity as possible. The geometric bits came from looking at the Kullback-Leibler decomposition of the log likelihood
![-\mathbb{E}[\log L(\theta|X)] = KL(P,Q_\theta) + \mathfrak{E}(P)](https://s0.wp.com/latex.php?latex=-%5Cmathbb%7BE%7D%5B%5Clog+L%28%5Ctheta%7CX%29%5D+%3D+KL%28P%2CQ_%5Ctheta%29+%2B+%5Cmathfrak%7BE%7D%28P%29&bg=000000&fg=B0B0B0&s=0&c=20201002)
where the expectation is computed under the true distribution P of the data X. And Qθ is the hypothesised distribution. A fine property of this decomposition is a statistical version of Pythagoreas’ theorem, namely that when the family of Qθ‘s is an exponential family, the Kullback-Leibler distance decomposes into

where θ⁰ is the expected maximum likelihood estimator of θ. (We also noticed this possibility of a decomposition in our Kullback-projection variable-selection paper with Jérôme Dupuis.) The talk by Aapo Hyvärinen this morning was related to Jean-François’ in that it used ICA all the way to a three-level representation if oriented towards natural vision modelling in connection with his book and the paper on unormalised models recently discussed on the ‘Og.
On the afternoon, Eric-Jan Wagenmaker [who persistently and rationally fight the (ab)use of p-values and who frequently figures on Andrew’s blog] gave a warning tutorial talk about the dangers of trusting p-values and going fishing for significance in existing studies, much in the spirit of Andrew’s blog (except for the defence of Bayes factors). Arguing in favour of preregistration. The talk was full of illustrations from psychology. And included the line that ESP testing is the jester of academia, meaning that testing for whatever form of ESP should be encouraged as a way to check testing procedures. If a procedure finds a significant departure from the null in this setting, there is something wrong with it! I was then reminded that Eric-Jan was one of the authors having analysed Bem’s controversial (!) paper on the “anomalous processes of information or energy transfer that are currently unexplained in terms of known physical or biological mechanisms”… (And of the shocking talk by Jessica Utts on the same topic I attended in Australia two years ago.)
 Another intriguing question on X validated (about an exercise in Jun Shao’s book) that made me realise a basic fact about exponential distributions. When considering two Exponential random variables X and Y with possibly different parameters λ and μ, Z⁺=max{X,Y} is dependent on the event X>Y while Z⁻=min{X,Y} is not (and distributed as an Exponential variate with parameter λ+μ.) Furthermore, Z⁺ is distributed from a signed mixture
Another intriguing question on X validated (about an exercise in Jun Shao’s book) that made me realise a basic fact about exponential distributions. When considering two Exponential random variables X and Y with possibly different parameters λ and μ, Z⁺=max{X,Y} is dependent on the event X>Y while Z⁻=min{X,Y} is not (and distributed as an Exponential variate with parameter λ+μ.) Furthermore, Z⁺ is distributed from a signed mixture
 When preparing my
When preparing my