 At Sylvia Richardson’s career celebration last Friday, I gave a talk on How many components in a mixture? which was most relevant given Sylvia’s contributions to mixture inference over the years, including her highly influential 1997 Read Paper with Peter Green. The other talks highlighted the many facets of Sylvia to the field and the profession, including obviously her MRC Unit directorship but also her RSS Presidency when she drove along with Chris Holmes the remarkable society’s response to the COVID pandemic. The day ended up with a diner in Emmanuel College (in the Dining Hall rather than the larger, noisier, and more formal Hall where I was once invited for the Midsummer Dinner by Sylvia). It was also a great opportunity to reconnect with friends I had not seen for ages.
At Sylvia Richardson’s career celebration last Friday, I gave a talk on How many components in a mixture? which was most relevant given Sylvia’s contributions to mixture inference over the years, including her highly influential 1997 Read Paper with Peter Green. The other talks highlighted the many facets of Sylvia to the field and the profession, including obviously her MRC Unit directorship but also her RSS Presidency when she drove along with Chris Holmes the remarkable society’s response to the COVID pandemic. The day ended up with a diner in Emmanuel College (in the Dining Hall rather than the larger, noisier, and more formal Hall where I was once invited for the Midsummer Dinner by Sylvia). It was also a great opportunity to reconnect with friends I had not seen for ages.
Archive for finite mixtures
Festschift for Sylvia
Posted in Books, pictures, Statistics, Travel, University life with tags Cam river, Cambridge colleges, Dirichlet process Gaussian mixture, distributed computing, Emmanuel College, Festschrift, finite mixtures, Midsummer, MRC Biostatistics Unit, RJMCMC, statistical evidence, Sylvia Richardson on May 17, 2023 by xi'anMike Titterington (1945-2023)
Posted in Books, Kids, pictures, Travel, University life with tags Biometrika, Edinburgh, editor, finite mixtures, Glasgow, memories, Mike Titterington, obituary, Scotland, University of Glasgow on April 14, 2023 by xi'an
Most sadly, I just heard from Glasgow that my friend and coauthor Mike Titterington passed away last weekend. While a significant figure in the field and a precursor in many ways, from mixtures to machine learning, Mike was one of the kindest persons ever, tolerant to a fault and generous with his time, and I enjoyed very much my yearly visits to Glasgow to work with him (and elope to the hills). This was also the time he was the (sole) editor of Biometrika and to this day I remain amazed at the amount of effort he dedicated to it, annotating every single accepted paper with his red pen during his morning bus commute and having the edited copy mailed to the author(s). The last time I saw him was in October 2019, when I was visiting the University of Edinburgh and the newly created Bayes Centre, and he came to meet me for an afternoon tea, despite being in poor health… Thank you for all these years, Mike!
signed mixtures [X’ed]
Posted in Books, Kids, Statistics with tags convolution, cross validated, finite mixtures, George Casella, Hospital's rule, hypoexponential distributions, matrix exponentiation, Michel de L'Hôpital, probability distribution on March 26, 2023 by xi'anFollowing a question on X validated, the hypoexponential distribution, I came across (for the second time) a realistic example of a mixture (of exponentials) whose density wrote as a signed mixture, i.e. involving both negative and positive weights (with sum still equal to one). Namely,
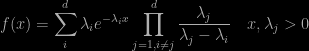
representing the density of a sum of d Exponential variates. The above is only well-defined when all rates differ, while a more generic definition involving matrix exponentiation exists. But the case when (only) two rates are equal can rather straightforwardly be derived by a direct application of L’Hospital rule, which my friend George considered as the number one calculus rule!
Finite mixture models do not reliably learn the number of components
Posted in Books, Statistics, University life with tags Bayes factor, David McKay, Edinburgh, empirical Bayes methods, finite mixtures, ICML 2021, infinite mixture, Mike Titterington, Padova, posterior concentration, Radford Neal, Scotland, Università degli studi di Padova, University of Glasgow on October 15, 2022 by xi'an When preparing my talk for Padova, I found that Diana Cai, Trevor Campbell, and Tamara Broderick wrote this ICML / PLMR paper last year on the impossible estimation of the number of components in a mixture.
When preparing my talk for Padova, I found that Diana Cai, Trevor Campbell, and Tamara Broderick wrote this ICML / PLMR paper last year on the impossible estimation of the number of components in a mixture.
“A natural check on a Bayesian mixture analysis is to establish that the Bayesian posterior on the number of components increasingly concentrates near the truth as the number of data points becomes arbitrarily large.” Cai, Campbell & Broderick (2021)
Which seems to contradict [my formerly-Glaswegian friend] Agostino Nobile who showed in his thesis that the posterior on the number of components does concentrate at the true number of components, provided the prior contains that number in its support. As well as numerous papers on the consistency of the Bayes factor, including the one against an infinite mixture alternative, as we discussed in our recent paper with Adrien and Judith. And reminded me of the rebuke I got in 2001 from the late David McKay when mentioning that I did not believe in estimating the number of components, both because of the impact of the prior modelling and of the tendency of the data to push for more clusters as the sample size increased. (This was a most lively workshop Mike Titterington and I organised at ICMS in Edinburgh, where Radford Neal also delivered an impromptu talk to argue against using the Galaxy dataset as a benchmark!)
“In principle, the Bayes factor for the MFM versus the DPM could be used as an empirical criterion for choosing between the two models, and in fact, it is quite easy to compute an approximation to the Bayes factor using importance sampling” Miller & Harrison (2018)
This is however a point made in Miller & Harrison (2018) that the estimation of k logically goes south if the data is not from the assumed mixture model. In this paper, Cai et al. demonstrate that the posterior diverges, even when it depends on the sample size. Or even the sample as in empirical Bayes solutions.
inferring the number of components [remotely]
Posted in Statistics with tags 8 Mile, Bayes factor, Bayesian consistency, Bayesian inference, COVID-19, Dirichlet process mixture, Eminem, evidence, finite mixtures, Italian Alps, Italy, mixture models, numerical integration, RJMCMC, slides, slideshare, University of Padova, unknown number of components on October 14, 2022 by xi'an
