 Once more, and thrice alas!, I became aware of a typo in our “Use R!” book through a question on X validated from a reader unable to reproduce the slice of a basic 2D slice sampler for a logistic regression with coefficients (a,b). Indeed, our slice reads as the incorrect set (missing the i=1,…,n)
Once more, and thrice alas!, I became aware of a typo in our “Use R!” book through a question on X validated from a reader unable to reproduce the slice of a basic 2D slice sampler for a logistic regression with coefficients (a,b). Indeed, our slice reads as the incorrect set (missing the i=1,…,n)
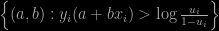
when it should have been
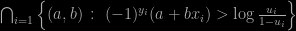
which is the version I found in my LaTeX file. So I do not know what happened (unless I corrected the LaTeX file at a later date and cannot remember it, but the latest chance on the file reads October 2011…). Fortunately, the resulting slices in a and b and the following R code remain correct. Unfortunately, both French and Japanese translations reproduce the mistake…





