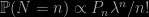A backward question from X validated as to why the above is a valid Normal generator based on exponential generations. Which can be found in most textbooks (if not ours). And in The Bible, albeit as an exercise. The validation proceeds from the (standard) Exponential density dominating the (standard) Normal density and, according to Devroye, may have originated from von Neumann himself. But with a brilliant reverse engineering resolution by W. Huber on X validated. While a neat exercise, it requires on average 2.64 Uniform generations per Normal generation, against a 1/1 ratio for Box-Muller (1958) polar approach, or 1/0.86 for the Marsaglia-Bray (1964) composition-rejection method. The apex of the simulation jungle is however Marsaglia and Tsang (2000) ziggurat algorithm. At least on CPUs since, Note however that “The ziggurat algorithm gives a more efficient method for scalar processors (e.g. old CPUs), while the Box–Muller transform is superior for processors with vector units (e.g. GPUs or modern CPUs)” according to Wikipedia.
To draw a comparison between this Normal generator (that I will consider as von Neumann’s) and the Box-Müller polar generator,
#Box-Müller
bm=function(N){
a=sqrt(-2*log(runif(N/2)))
b=2*pi*runif(N/2)
return(c(a*sin(b),a*cos(b)))
}
#vonNeumann
vn=function(N){
u=-log(runif(2.64*N))
v=-2*log(runif(2.64*N))>(u-1)^2
w=(runif(2.64*N)<.5)-2
return((w*u)[v])
}
here are the relative computing times
> system.time(bm(1e8))
utilisateur système écoulé
7.015 0.649 7.674
> system.time(vn(1e8))
utilisateur système écoulé
42.483 5.713 48.222