
Archive for Buffon’s needle
Bayesian inference from the ground up [no book review]
Posted in Books, Kids, Statistics, University life with tags Archimedes death ray, Bayes theorem, Bayesian Inference for Psychological Science, Bayesian inference from the ground up, Bayesian textbook, Bayesian Thinking for Toddlers, book cover, Buffon's needle, E.J. Wagenmakers, French history, Jardin des Plantes, not a book review, Paris, University of Amsterdam on November 7, 2023 by xi'an
dial e for Buffon
Posted in Books, Kids, Statistics with tags Alfréd Rényi, arithmétique morale, Buffon's needle, e, exponentiation, π, Monte Carlo approximations, The Riddler on January 29, 2021 by xi'an The use of Buffon’s needle to approximate π by a (slow) Monte Carlo estimate is a well-known Monte Carlo illustration. But that a similar experiment can be used for approximating e seems less known, if judging from the 08 January riddle from The Riddler. When considering a sequence of length n exchangeable random variables, the probability of a particuliar ordering of the sequence is 1/n!. Thus, counting how many darts need be thrown on a target until the distance to the centre increases produces a random number N≥2 with pmf 1/n!-1/(n+1)! and with expectation equal to e. Which can be checked as follows
The use of Buffon’s needle to approximate π by a (slow) Monte Carlo estimate is a well-known Monte Carlo illustration. But that a similar experiment can be used for approximating e seems less known, if judging from the 08 January riddle from The Riddler. When considering a sequence of length n exchangeable random variables, the probability of a particuliar ordering of the sequence is 1/n!. Thus, counting how many darts need be thrown on a target until the distance to the centre increases produces a random number N≥2 with pmf 1/n!-1/(n+1)! and with expectation equal to e. Which can be checked as follows
p=diff(c(0,1+which(diff(rt(1e5))>0))) sum((p>1)*((p+1)*(p+2)/2-1)+2*(p==1))
which recycles simulations by using every one as starting point (codegolfers welcome!).
An earlier post on the ‘Og essentially covered the same notion, also linking it to Forsythe’s method and to Gnedenko. (Rényi could also be involved!) Paradoxically, the extra-credit given to the case when the target is divided into equal distance tori is much less exciting…
Buffon machines
Posted in Books, pictures, Statistics, University life with tags Bernoulli factory, Buffon machines, Buffon's needle, Geometric distribution, George Louis Leclerc, John von Neumann, logarithmic distribution, Luc Devroye, Poisson distribution on December 22, 2020 by xi'an
By chance I came across a 2010 paper entitled On Buffon Machines and Numbers by Philippe Flajolet, Maryse Pelletier and Michèle Soria. Which relates to Bernoulli factories, a related riddle, and the recent paper by Luis Mendo I reviewed here. What the authors call a Buffon machine is a device that produces a perfect simulation of a discrete random variable out of a uniform bit generator. Just like (George Louis Leclerc, comte de) Buffon’s needle produces a Bernoulli outcome with success probability π/4. out of a real Uniform over (0,1). Turned into a sequence of Uniform random bits.
“Machines that always halt can only produce Bernoulli distributions whose parameter is a dyadic rational.”
When I first read this sentence it seemed to clash with the earlier riddle, until I realised the later started from a B(p) coin to produce a fair coin, while this paper starts with a fair coin.
The paper hence aims at a version of the Bernoulli factory problem (see Definition 2), although the term is only mentioned at the very end, with the added requirement of simplicity and conciseness translated as a finite expected number of draws and possibly an exponential tail.
It first recalls the (Forsythe–)von Neumann method of generating exponential (and other) variates out of a Uniform generator (see Section IV.2 in Devroye’s generation bible). Expanded into a general algorithm for generating discrete random variables whose pmf’s are related to permutation cardinals,
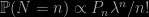
if the Bernoulli generator has probability λ. These include the Poisson and the logarithmic distributions and as a side product Bernoulli distributions with some logarithmic, exponential and trigonometric transforms of λ.
As a side remark, a Bernoulli generator with probability 1/π is derived from Ramanujan identity

as “a discrete analogue of Buffon’s original. In a neat connection with Mendo’s paper, the authors of this 2010 paper note that Euler’s constant does not appear to be achievable by a Buffon machine.
certified RNGs
Posted in Statistics with tags Buffon's needle, DieHard, gaming, Gaming Laboratories International, George Marsaglia, random number generator, randomness, RNG on April 27, 2020 by xi'an A company called Gaming Laboratories International (GLI) is delivering certificates of randomness. Apparently using Marsaglia’s DieHard tests. Here are some unforgettable quotes from their webpage:
A company called Gaming Laboratories International (GLI) is delivering certificates of randomness. Apparently using Marsaglia’s DieHard tests. Here are some unforgettable quotes from their webpage:
“…a Random Number Generator (RNG) is a key component that MUST be adequately and fully tested to ensure non-predictability and no biases exist towards certain game outcomes.”
“GLI has the most experienced and robust RNG testing methodologies in the world. This includes software-based (pseudo-algorithmic) RNG’s, Hardware RNG’s, and hybrid combinations of both.”
“GLI uses custom software written and validated through the collaborative effort of our in-house mathematicians and industry consultants since our inception in 1989. An RNG Test Suite is applied for randomness testing.”
“No lab in the world provides the level of iGaming RNG assurance that GLI does. Don’t take a chance with this most critical portion of your iGaming system.”
The answer is e, what was the question?!
Posted in Books, R, Statistics with tags Buffon's needle, cross validated, Gnedenko, Monte Carlo integration, Poisson process, simulation on February 12, 2016 by xi'an A rather exotic question on X validated: since π can be approximated by random sampling over a unit square, is there an equivalent for approximating e? This is an interesting question, as, indeed, why not focus on e rather than π after all?! But very quickly the very artificiality of the problem comes back to hit one in one’s face… With no restriction, it is straightforward to think of a Monte Carlo average that converges to e as the number of simulations grows to infinity. However, such methods like Poisson and normal simulations require some complex functions like sine, cosine, or exponential… But then someone came up with a connection to the great Russian probabilist Gnedenko, who gave as an exercise that the average number of uniforms one needs to add to exceed 1 is exactly e, because it writes as
A rather exotic question on X validated: since π can be approximated by random sampling over a unit square, is there an equivalent for approximating e? This is an interesting question, as, indeed, why not focus on e rather than π after all?! But very quickly the very artificiality of the problem comes back to hit one in one’s face… With no restriction, it is straightforward to think of a Monte Carlo average that converges to e as the number of simulations grows to infinity. However, such methods like Poisson and normal simulations require some complex functions like sine, cosine, or exponential… But then someone came up with a connection to the great Russian probabilist Gnedenko, who gave as an exercise that the average number of uniforms one needs to add to exceed 1 is exactly e, because it writes as

(The result was later detailed in the American Statistician as an introductory simulation exercise akin to Buffon’s needle.) This is a brilliant solution as it does not involve anything but a standard uniform generator. I do not think it relates in any close way to the generation from a Poisson process with parameter λ=1 where the probability to exceed one in one step is e⁻¹, hence deriving a Geometric variable from this process leads to an unbiased estimator of e as well. As an aside, W. Huber proposed the following elegantly concise line of R code to implement an approximation of e:
1/mean(n*diff(sort(runif(n+1))) > 1)
Hard to beat, isn’t it?! (Although it is more exactly a Monte Carlo approximation of

which adds a further level of approximation to the solution….)
