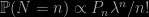“In recent years, the Rejection Monte Carlo (RMC) algorithm has emerged sporadically in literature under alternative names such as screening sampling or reject-accept sampling algorithms”
First, I was intrigued enough by a new arXival spotted in the Thalys train from Brussels to take a deeper look at it, but soon realised there was nothing of substance in the paper. Which solely recalls the fundamental of (accept-)reject algorithms, invented in the early days of computer simulation by von Neumann (even though the preprint refers to much more recent publications). Without providing the average acceptance probability as being equal to the inverse of the bounding constant [independently of the dimension of the random variable] and no mention of The Bible either… But with a standard depiction of accepted vs rejected points as uniformly dispersed on the subgraph of the proposal (as in the above taken from our very own Monte Carlo statistical Methods). Funnily enough, the most basic rejection algorithm, that is, the one based on a uniform sampling from a bounding (hyper)box is illustrated for a Normal target, although the latter has infinite support. And the paper seems to conclude on the appeal of using uniform proposals over bounding boxes, even though the increasing inefficiency against the dimension is well-known. A very simple rejection then, indeed!