 Panayiota Touloupou (Warwick), Naif Alzahrani, Peter Neal, Simon Spencer (Warwick) and Trevelyan McKinley arXived a paper yesterday on Model comparison with missing data using MCMC and importance sampling, where they proposed an importance sampling strategy based on an early MCMC run to approximate the marginal likelihood a.k.a. the evidence. Another instance of estimating a constant. It is thus similar to our Frontier paper with Jean-Michel, as well as to the recent Pima Indian survey of James and Nicolas. The authors give the difficulty to calibrate reversible jump MCMC as the starting point to their research. The importance sampler they use is the natural choice of a Gaussian or t distribution centred at some estimate of θ and with covariance matrix associated with Fisher’s information. Or derived from the warmup MCMC run. The comparison between the different approximations to the evidence are done first over longitudinal epidemiological models. Involving 11 parameters in the example processed therein. The competitors to the 9 versions of importance samplers investigated in the paper are the raw harmonic mean [rather than our HPD truncated version], Chib’s, path sampling and RJMCMC [which does not make much sense when comparing two models]. But neither bridge sampling, nor nested sampling. Without any surprise (!) harmonic means do not converge to the right value, but more surprisingly Chib’s method happens to be less accurate than most importance solutions studied therein. It may be due to the fact that Chib’s approximation requires three MCMC runs and hence is quite costly. The fact that the mixture (or defensive) importance sampling [with 5% weight on the prior] did best begs for a comparison with bridge sampling, no? The difficulty with such study is obviously that the results only apply in the setting of the simulation, hence that e.g. another mixture importance sampler or Chib’s solution would behave differently in another model. In particular, it is hard to judge of the impact of the dimensions of the parameter and of the missing data.
Panayiota Touloupou (Warwick), Naif Alzahrani, Peter Neal, Simon Spencer (Warwick) and Trevelyan McKinley arXived a paper yesterday on Model comparison with missing data using MCMC and importance sampling, where they proposed an importance sampling strategy based on an early MCMC run to approximate the marginal likelihood a.k.a. the evidence. Another instance of estimating a constant. It is thus similar to our Frontier paper with Jean-Michel, as well as to the recent Pima Indian survey of James and Nicolas. The authors give the difficulty to calibrate reversible jump MCMC as the starting point to their research. The importance sampler they use is the natural choice of a Gaussian or t distribution centred at some estimate of θ and with covariance matrix associated with Fisher’s information. Or derived from the warmup MCMC run. The comparison between the different approximations to the evidence are done first over longitudinal epidemiological models. Involving 11 parameters in the example processed therein. The competitors to the 9 versions of importance samplers investigated in the paper are the raw harmonic mean [rather than our HPD truncated version], Chib’s, path sampling and RJMCMC [which does not make much sense when comparing two models]. But neither bridge sampling, nor nested sampling. Without any surprise (!) harmonic means do not converge to the right value, but more surprisingly Chib’s method happens to be less accurate than most importance solutions studied therein. It may be due to the fact that Chib’s approximation requires three MCMC runs and hence is quite costly. The fact that the mixture (or defensive) importance sampling [with 5% weight on the prior] did best begs for a comparison with bridge sampling, no? The difficulty with such study is obviously that the results only apply in the setting of the simulation, hence that e.g. another mixture importance sampler or Chib’s solution would behave differently in another model. In particular, it is hard to judge of the impact of the dimensions of the parameter and of the missing data.
Archive for mixture
approximating evidence with missing data
Posted in Books, pictures, Statistics, University life with tags Bayes factor, Bayesian Choice, Bayesian model comparison, bridge sampling, Chib's approximation, defensive mixture, harmonic mean, importance sampling, MCMC algorithms, mixture, Monte Carlo Statistical Methods, nested sampling, Pima Indians, reversible jump MCMC, simulation, University of Warwick on December 23, 2015 by xi'ana simulated annealing approach to Bayesian inference
Posted in Books, pictures, Statistics, University life with tags ABC, ABC-MCMC, ABC-SMC, Bayesian Analysis, endoreversibility, mixture, Monte Carlo Statistical Methods, particle system, sequential Monte Carlo, simulated annealing, Switzerland on October 1, 2015 by xi'an A misleading title if any! Carlos Albert arXived a paper with this title this morning and I rushed to read it. Because it sounded like Bayesian analysis could be expressed as a special form of simulated annealing. But it happens to be a rather technical sequel [“that complies with physics standards”] to another paper I had missed, A simulated annealing approach to ABC, by Carlos Albert, Hans Künsch, and Andreas Scheidegger. Paper that appeared in Statistics and Computing last year, and which is most interesting!
A misleading title if any! Carlos Albert arXived a paper with this title this morning and I rushed to read it. Because it sounded like Bayesian analysis could be expressed as a special form of simulated annealing. But it happens to be a rather technical sequel [“that complies with physics standards”] to another paper I had missed, A simulated annealing approach to ABC, by Carlos Albert, Hans Künsch, and Andreas Scheidegger. Paper that appeared in Statistics and Computing last year, and which is most interesting!
“These update steps are associated with a flow of entropy from the system (the ensemble of particles in the product space of parameters and outputs) to the environment. Part of this flow is due to the decrease of entropy in the system when it transforms from the prior to the posterior state and constitutes the well-invested part of computation. Since the process happens in finite time, inevitably, additional entropy is produced. This entropy production is used as a measure of the wasted computation and minimized, as previously suggested for adaptive simulated annealing” (p.3)
The notion behind this simulated annealing intrusion into the ABC world is that the choice of the tolerance can be adapted along iterations according to a simulated annealing schedule. Both papers make use of thermodynamics notions that are completely foreign to me, like endoreversibility, but aim at minimising the “entropy production of the system, which is a measure for the waste of computation”. The central innovation is to introduce an augmented target on (θ,x) that is
f(x|θ)π(θ)exp{-ρ(x,y)/ε},
where ε is the tolerance, while ρ(x,y) is a measure of distance to the actual observations, and to treat ε as an annealing temperature. In an ABC-MCMC implementation, the acceptance probability of a random walk proposal (θ’,x’) is then
exp{ρ(x,y)/ε-ρ(x’,y)/ε}∧1.
Under some regularity constraints, the sequence of targets converges to
π(θ|y)exp{-ρ(x,y)},
if ε decreases slowly enough to zero. While the representation of ABC-MCMC through kernels other than the Heaviside function can be found in the earlier ABC literature, the embedding of tolerance updating within the modern theory of simulated annealing is rather exciting.
“Furthermore, we will present an adaptive schedule that attempts convergence to the correct posterior while minimizing the required simulations from the likelihood. Both the jump distribution in parameter space and the tolerance are adapted using mean fields of the ensemble.” (p.2)
What I cannot infer from a rather quick perusal of the papers is whether or not the implementation gets into the way of the all-inclusive theory. For instance, how can the Markov chain keep moving as the tolerance gets to zero? Even with a particle population and a sequential Monte Carlo implementation, it is unclear why the proposal scale factor [as in equation (34)] does not collapse to zero in order to ensure a non-zero acceptance rate. In the published paper, the authors used the same toy mixture example as ours [from Sisson et al., 2007], where we earned the award of the “incredibly ugly squalid picture”, with improvements in the effective sample size, but this remains a toy example. (Hopefully a post to be continued in more depth…)
a vignette on Metropolis
Posted in Books, Kids, R, Statistics, Travel, University life with tags Columbia University, Introducing Monte Carlo Methods with R, Metropolis-Hastings algorithm, mixture, New York city, testing as mixture estimation, vignette on April 13, 2015 by xi'an
 Over the past week, I wrote a short introduction to the Metropolis-Hastings algorithm, mostly in the style of our Introduction to Monte Carlo with R book, that is, with very little theory and worked-out illustrations on simple examples. (And partly over the Atlantic on my flight to New York and Columbia.) This vignette is intended for the Wiley StatsRef: Statistics Reference Online Series, modulo possible revision. Again, nothing novel therein, except for new examples.
Over the past week, I wrote a short introduction to the Metropolis-Hastings algorithm, mostly in the style of our Introduction to Monte Carlo with R book, that is, with very little theory and worked-out illustrations on simple examples. (And partly over the Atlantic on my flight to New York and Columbia.) This vignette is intended for the Wiley StatsRef: Statistics Reference Online Series, modulo possible revision. Again, nothing novel therein, except for new examples.
mixtures of mixtures
Posted in pictures, Statistics, University life with tags arXiv, Austria, clustering, k-mean clustering algorithm, Linkz, map, MCMC, mixture, overfitting, Wien on March 9, 2015 by xi'an And yet another arXival of a paper on mixtures! This one is written by Gertraud Malsiner-Walli, Sylvia Frühwirth-Schnatter, and Bettina Grün, from the Johannes Kepler University Linz and the Wirtschaftsuniversitat Wien I visited last September. With the exact title being Identifying mixtures of mixtures using Bayesian estimation.
And yet another arXival of a paper on mixtures! This one is written by Gertraud Malsiner-Walli, Sylvia Frühwirth-Schnatter, and Bettina Grün, from the Johannes Kepler University Linz and the Wirtschaftsuniversitat Wien I visited last September. With the exact title being Identifying mixtures of mixtures using Bayesian estimation.
So, what is a mixture of mixtures if not a mixture?! Or if not only a mixture. The upper mixture level is associated with clusters, while the lower mixture level is used for modelling the distribution of a given cluster. Because the cluster needs to be real enough, the components of the mixture are assumed to be heavily overlapping. The paper thus spends a large amount of space on detailing the construction of the associated hierarchical prior. Which in particular implies defining through the prior what a cluster means. The paper also connects with the overfitting mixture idea of Rousseau and Mengersen (2011, Series B). At the cluster level, the Dirichlet hyperparameter is chosen to be very small, 0.001, which empties superfluous clusters but sounds rather arbitrary (which is the reason why we did not go for such small values in our testing/mixture modelling). On the opposite, the mixture weights have an hyperparameter staying (far) away from zero. The MCMC implementation is based on a standard Gibbs sampler and the outcome is analysed and sorted by estimating the “true” number of clusters as the MAP and by selecting MCMC simulations conditional on that value. From there clusters are identified via the point process representation of a mixture posterior. Using a standard k-means algorithm.
The remainder of the paper illustrates the approach on simulated and real datasets. Recovering in those small dimension setups the number of clusters used in the simulation or found in other studies. As noted in the conclusion, using solely a Gibbs sampler with such a large number of components is rather perilous since it may get stuck close to suboptimal configurations. Especially with very small Dirichlet hyperparameters.
ABC for missing data
Posted in Statistics, University life with tags ANC, HMM, joint distribution, marginal, mixture, semi-automatic ABC, summary statistics on February 2, 2012 by xi'anI received this email a few days ago:
I am an hard-core reader of your blog and thanks to your posts I have recently started being interested to ABC (and Bayesian methods in general). I am writing you to ask for suggestions on the application of the semi-automatic ABC à la Fearnhead & Prangle. The reason why I am contacting you instead of addressing the authors is because (i) you have been involved in the RSS reading of their paper and (ii) you are an authority on ABC, and therefore you are probably best suited and less biased on such issue. I am applying ABC with the semi-automatic statistics selection provided in Fearnhead and Prangle (2012) to a problem which can be formalized as a hidden Markov model. However I am unsure of whether I am making a huge mistake on the following point: let’s suppose we have an unobserved (latent) system state X (depending on an unknown parameter θ) and a corresponding “corrupted” version which is observed with some measurement error, e.g.
Y = X + ε,
where ε is the measurement error independent of X, ε is N(0, σ²), say. Now their setup does not consider measurement error, so I wonder if the following is correct. Since I can simulate n times some X’ from p(X|θ) am I allowed to use the corresponding “simulated” n corrupted measurements
Y’ = X’ + ε’
(where ε’ is a draw from p(ε|σ)) into their regression approach to determine a (vector of) summary statistic S=(S1,S2) for (θ,σ)? I mean the Y’ are draws from a p(y|X’,θ,σ) which is conditional on X’. Is this allowed? Wilkinson (2008) is the only reference I have found considering ABC with measurement-error (the ones by Dean et al (2011) and Jasra et al (2011) being too technical in my opinion to allow a practical implementation) and since he does not consider a summary statistics-based approach (e.g. Algorithm D, page 10) of course he is not in need to simulate the corrupted measurements but only the latent ones. Therefore I am a bit unsure on whether it is statistically ok to simulate Y’ conditionally on X’ or if there is some theoretical issue that makes this nonsense.
to which I replied
…about your model and question, there is no theoretical difficulty in simulating x’ then y’given x’ and a value of the parameters. The reason is that
.the proper marginal as defined by the model. Using the intermediate x’ is a way to bypass the integral but this is 100% correct!…
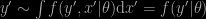
a reply followed by a further request for precision
Although your equation is clearly true, I am not sure I fully grasp the issue, so I am asking for confirmation. Yes, as you noticed I need a
y’ ~ f(y’|θ,σ)
Now it’s certainly true that I can generate a draw x’ from f(x’|θ,σ) and then plug such x’ into f(y’|x’,θ,σ) to generate y’. By proceeding this way I obtain a draw (y’,x’) from f(y’,x’|θ,σ). I think I understood your reasoning, on how by using the procedure above I am actually skipping the computation of the integral in:
Is it basically the case that the mechanism above is just a classic simulation from a bivariate distribution, where since I am interested in the marginal f(y’|θ,σ) I simulate from the joint density f(y’,x’|θ,σ) and then discard the x’ output?

which is indeed a correct interpretation. When simulating from a joint, the marginals are by-products of the simulation.
