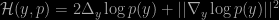When preparing my talk for Padova, I found that Diana Cai, Trevor Campbell, and Tamara Broderick wrote this ICML / PLMR paper last year on the impossible estimation of the number of components in a mixture.
When preparing my talk for Padova, I found that Diana Cai, Trevor Campbell, and Tamara Broderick wrote this ICML / PLMR paper last year on the impossible estimation of the number of components in a mixture.
“A natural check on a Bayesian mixture analysis is to establish that the Bayesian posterior on the number of components increasingly concentrates near the truth as the number of data points becomes arbitrarily large.” Cai, Campbell & Broderick (2021)
Which seems to contradict [my formerly-Glaswegian friend] Agostino Nobile who showed in his thesis that the posterior on the number of components does concentrate at the true number of components, provided the prior contains that number in its support. As well as numerous papers on the consistency of the Bayes factor, including the one against an infinite mixture alternative, as we discussed in our recent paper with Adrien and Judith. And reminded me of the rebuke I got in 2001 from the late David McKay when mentioning that I did not believe in estimating the number of components, both because of the impact of the prior modelling and of the tendency of the data to push for more clusters as the sample size increased. (This was a most lively workshop Mike Titterington and I organised at ICMS in Edinburgh, where Radford Neal also delivered an impromptu talk to argue against using the Galaxy dataset as a benchmark!)
“In principle, the Bayes factor for the MFM versus the DPM could be used as an empirical criterion for choosing between the two models, and in fact, it is quite easy to compute an approximation to the Bayes factor using importance sampling” Miller & Harrison (2018)
This is however a point made in Miller & Harrison (2018) that the estimation of k logically goes south if the data is not from the assumed mixture model. In this paper, Cai et al. demonstrate that the posterior diverges, even when it depends on the sample size. Or even the sample as in empirical Bayes solutions.