
, as well as being less excited by the contents of submissions since most were outside my area of direct interest.")
Archive for statistical inference
Bye’ ometrika
Posted in Books, pictures, Statistics, University life with tags academic publisher, associate editor, Biometrika, Biometrika Trust, commercial editing, editor, large-scale statistical learning, peer review, refereeing, statistical inference, statistical machine learning, Statistics on February 1, 2024 by xi'an
Ocean’s four!
Posted in Books, pictures, Statistics, University life with tags #ERCSyG, Bayesian Analysis, Brussels, data privacy, data processing, decentralized networks, decision-making agents, ERC, European Research Council, machine learning, multi-agent decision theory, murmuration, Ocean, probabilistic machine learning, starlings, statistical inference, stochastic optimization, The Ocean at the End of the Lane, uncertainty quantification, whales on October 25, 2022 by xi'an
Fantastic news! The ERC-Synergy¹ proposal we submitted last year with Michael Jordan, Éric Moulines, and Gareth Roberts has been selected by the ERC (which explains for the trips to Brussels last month). Its acronym is OCEAN [hence the whale pictured by a murmuration of starlings!], which stands for On intelligenCE And Networks: Mathematical and Algorithmic Foundations for Multi-Agent Decision-Making. Here is the abstract, which will presumably turn public today along with the official announcement from the ERC:
Until recently, most of the major advances in machine learning and decision making have focused on a centralized paradigm in which data are aggregated at a central location to train models and/or decide on actions. This paradigm faces serious flaws in many real-world cases. In particular, centralized learning risks exposing user privacy, makes inefficient use of communication resources, creates data processing bottlenecks, and may lead to concentration of economic and political power. It thus appears most timely to develop the theory and practice of a new form of machine learning that targets heterogeneous, massively decentralized networks, involving self-interested agents who expect to receive value (or rewards, incentive) for their participation in data exchanges.
OCEAN will develop statistical and algorithmic foundations for systems involving multiple incentive-driven learning and decision-making agents, including uncertainty quantification at the agent’s level. OCEAN will study the interaction of learning with market constraints (scarcity, fairness), connecting adaptive microeconomics and market-aware machine learning.
OCEAN builds on a decade of joint advances in stochastic optimization, probabilistic machine learning, statistical inference, Bayesian assessment of uncertainty, computation, game theory, and information science, with PIs having complementary and internationally recognized skills in these domains. OCEAN will shed a new light on the value and handling data in a competitive, potentially antagonistic, multi-agent environment, and develop new theories and methods to address these pressing challenges. OCEAN requires a fundamental departure from standard approaches and leads to major scientific interdisciplinary endeavors that will transform statistical learning in the long term while opening up exciting and novel areas of research.
Since the ERC support in this grant mostly goes to PhD and postdoctoral positions, watch out for calls in the coming months or contact us at any time.
a random day, in Paris
Posted in Statistics, University life with tags conference, IHP, Institut Henri Poincaré, journée aléatoire, probability theory, SFDS, SMAI, SMF, statistical inference, Statistics on September 28, 2022 by xi'an
One statistical analysis must not rule them all
Posted in Books, pictures, Statistics, University life with tags agent-based models, Alfred Korzybski, all models are wrong, COVID-19, decision making, difference, multi-analyst projects, Nature, Science, statistical inference, statistical modelling on May 31, 2022 by xi'an E.J. (Wagenmakers), along with co-authors, published a (long) comment in Nature, rewarded by a illustration by David Parkins! About the over-confidence often carried by (single) statistical analyses, meaning a call for the comparison below different datasets, different models, and different techniques (beyond different teams).
E.J. (Wagenmakers), along with co-authors, published a (long) comment in Nature, rewarded by a illustration by David Parkins! About the over-confidence often carried by (single) statistical analyses, meaning a call for the comparison below different datasets, different models, and different techniques (beyond different teams).
“To gauge the robustness of their conclusions, researchers should subject the data to multiple analyses; ideally, these would be carried out by one or more independent teams. We understand that this is a big shift in how science is done, that appropriate infrastructure and incentives are not yet in place, and that many researchers will recoil at the idea as being burdensome and impractical. Nonetheless, we argue that the benefits of broader, more-diverse approaches to statistical inference could be so consequential that it is imperative to consider how they might be made routine.”
If COVID-19 had one impact on the general public perception of modelling, it is that, to quote Alfred Korzybski, the map is not the territory, i.e., the model is not reality. Hence, the outcome of a model-based analysis, including its uncertainty assessment, depends on the chosen model. And does not include the bias due to this choice. Which is much more complex to ascertain in a sort of things that we do not know we do not know paradigm…. In other words, while we know that all models are wrong, we do not know how much wrong each model is. Except that they disagree with one another in experiments like the above.
“Less understood is how restricting analyses to a single technique effectively blinds researchers to an important aspect of uncertainty, making results seem more precise than they really are.”
The difficulty with E.J.’s proposal is to set a framework for a range of statistical analyses. To which extent should one seek a different model or a different analysis? How can we weight the multiple analyses? Which probabilistic meaning can we attach to the uncertainty between analyses? How quickly will opportunistic researchers learn to play against the house and pretend at objectivity? Isn’t statistical inference already equipped to handle multiple models?
likelihood inference with no MLE
Posted in Books, R, Statistics with tags exponential families, maximum likelihood estimation, R package, rcdd, statistical inference on July 29, 2021 by xi'an“In a regular full discrete exponential family, the MLE for the canonical parameter does not exist when the observed value of the canonical statistic lies on the boundary of its convex support.”
Daniel Eck and Charlie Geyer just published an interesting and intriguing paper on running efficient inference for discrete exponential families when the MLE does not exist. As for instance in the case of a complete separation between 0’s and 1’s in a logistic regression model. Or more generally, when the estimated Fisher information matrix is singular. Not mentioning the Bayesian version, which remains a form of likelihood inference. The construction is based on a MLE that exists on an extended model, a notion which I had not heard previously. This model is defined as a limit of likelihood values
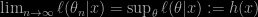
called the MLE distribution. Which remains a mystery to me, to some extent. Especially when this distribution is completely degenerate. Examples provided within the paper alas do not help, as they mostly serve as illustration for the associated rcdd R package. Intriguing, indeed!
