Julien Cornebise posted a rather detailed set of comments (from Jasper!) that I thought was interesting and thought-provoking enough (!) to promote to a guest post. Here it is , then, to keep the debate rolling (with my only censoring being the removal of smileys!). (Please keep in mind that I do not endorse everything stated in this guest post! Especially the point on “Use R!“)
On C vs R
As a reply to Duncan: indeed C (at least for the bottlenecks) will probably always be faster for the final, mainstream use of an algorithm [e.g. as a distributed R library, or a standalone program]. Machine-level, smart compilers, etc etc. The same goes for Matlab, and even for Python: e.g. Pierre Jacob (Xian’s great PhD student) uses Weave to inline C in his Python code for the bottlenecks — simple, and fast. Some hedge funds even hire coders to recode the Matlab code of their consulting academic statisticians.
Point taken. But, as Radford Neal points out, that doesn’t justify R to be much slower that it could be:
- When statisticians (cf Xian) want to develop/prototype new algorithms and methods while focussing on the math/stat/algo more than on the language-dependent implementation, it is still a shame to waste 50% (or even 25%). Same goes for the memory management, or even for some language features[1]
- Even less computer-savvy users of R for real-case data, willing to use existing algorithms (not developing new algos) but on big/intricate datasets can be put off by slow speed — or even by memory failures.
- And the library is BRILLIANT.
On Future Language vs R
Thanks David and Martyn for the link to Ihaka’s great paper on R-like lisp-based. Says things better than I could, and with an expertise on R that I haven’t. I also didn’t know about Robert Gentleman and his success at Harvard (but he *invented* the thing, not merely tuned it up).
Developing a whole new language and concept, as advocated in Ihaka’s paper and as suggested by gappy3000 would be a great leap forward, and a needed breakthrough to change the way we use computational stats. I would *love* to see that, as I personally think (as Ihaka advocates in the paper you link to) that R, as a language, is a hell of a pain [2] and I am saddened to see a lot of “Use R” books who will root its inadequate use for needs where the language hardly fits the bill — although the library does.
But R is here and in everyday use, and the matter is more of making it worth using, to its full potential. I have no special attachment to R, but any breakthrough language that would not be entirely compatible with the massive library contributed over the years would be doomed to fail to pick-up the everyday statistician—and we’re talking here about far-fetched long-term moves. Sanitary breakthrough, but harder to make happen when such an anchor is here.
I would say that R has turned into the Fortran of statistics: here to stay, anchored by the inertia that stems from its intrinsic (and widely acknowledged) merits (I’ve been nice, I didn’t say Cobol.).
So until of the great leap forward comes (or until we make it happen as a community), I second Radford Neal‘s call for optimization of the existing core of R.
Rejoinder
As a rejoinder to the comments here, I think we need to consider separately
- R’s brilliant library
- R’s not-so-brilliant language and/or interpreter.
It seems to me from this topic that the community needs/should push for, in chronological order.
- First, a speed-up of R’s existing interpreter as called for by Radford Neal. “Easy” and short-term task, by good-willing amateur coders, or, better, by solid CS people.
- Team-up with CS experts interested in developing computational stat-related tools.
- With them, get out of the now dead-ended R language and embark on a new stat framework based on an *existing*, proven, language. *Must* be able to reuse the brilliant R library/codes brought up by the community. Failing so would fail to pick up the userbase = die in limbo. That’s more or less what is called for by Ihaka (except for his doubts on the backward compatibility, see Section 7 of his paper). Much harder and longer term, but worth it.
From then on
Who knows the R community enough to relay this call, and make it happen ? I’m out of my league.
Uninteresting footnotes:
[1] I have twitched several times when trying R, feeling the coding was somewhat unnatural from a CS point of view. [Mind, I twitch all the same, although on other points, with Matlab]
[2] again, I speak only out of the few tries I gave it, as I gave up using it for my everyday work, I am biased — and ignorant
Neal
 Once more, and thrice alas!, I became aware of a typo in our “Use R!” book through a question on X validated from a reader unable to reproduce the slice of a basic 2D slice sampler for a logistic regression with coefficients (a,b). Indeed, our slice reads as the incorrect set (missing the i=1,…,n)
Once more, and thrice alas!, I became aware of a typo in our “Use R!” book through a question on X validated from a reader unable to reproduce the slice of a basic 2D slice sampler for a logistic regression with coefficients (a,b). Indeed, our slice reads as the incorrect set (missing the i=1,…,n)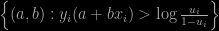
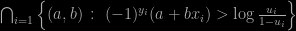






{kind=link}