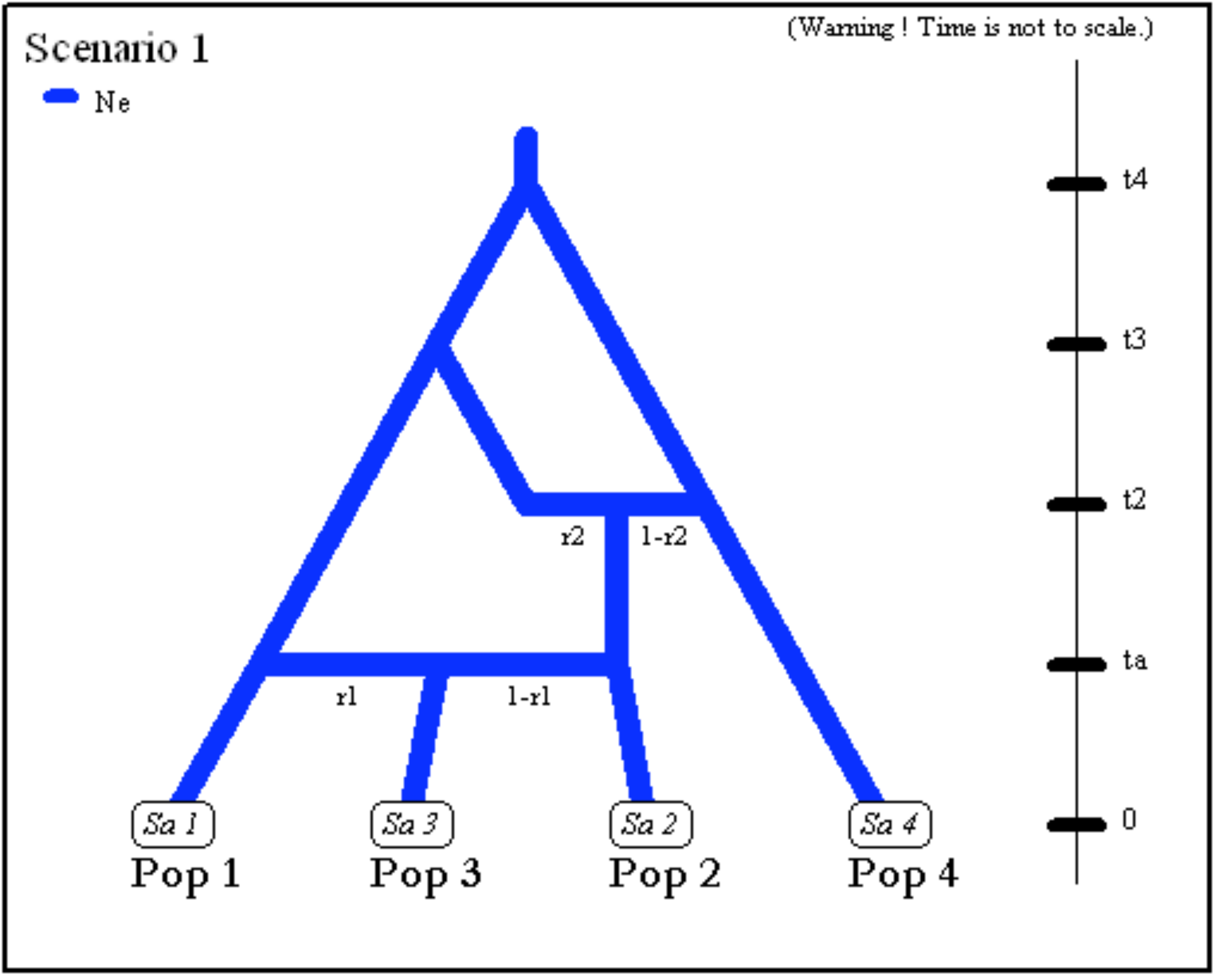
My friends and co-authors from Montpellier have released last month the third version of the DIYABC software, DIYABC-RF, which includes and promotes the use of random forests for parameter inference and model selection, in connection with Louis Raynal’s thesis. Intended as the earlier versions of DIYABC for population genetic applications. Bienvenue!!!
The software DIYABC Random Forest (hereafter DIYABC-RF) v1.0 is composed of three parts: the dataset simulator, the Random Forest inference engine and the graphical user interface. The whole is packaged as a standalone and user-friendly graphical application named DIYABC-RF GUI and available at https://diyabc.github.io. The different developer and user manuals for each component of the software are available on the same website. DIYABC-RF is a multithreaded software on three operating systems: GNU/Linux, Microsoft Windows and MacOS. One can use the program can be used through a modern and user-friendly graphical interface designed as an R shiny application (Chang et al. 2019). For a fluid and simplified user experience, this interface is available through a standalone application, which does not require installing R or any dependencies and hence can be used independently. The application is also implemented in an R package providing a standard shiny web application (with the same graphical interface) that can be run locally as any shiny application, or hosted as a web service to provide a DIYABC-RF server for multiple users.