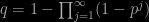A question from X validated had enough appeal for me to procrastinate about it for ½ an hour: what difference does it make [for simulation purposes] that a target density is properly normalised? In the continuous case, I do not see much to exploit about this knowledge, apart from the value potentially leading to a control variate (in a Gelfand and Dey 1996 spirit) and possibly to a stopping rule (by checking that the portion of the space visited so far has mass close to one, but this is more delicate than it sounds).
A question from X validated had enough appeal for me to procrastinate about it for ½ an hour: what difference does it make [for simulation purposes] that a target density is properly normalised? In the continuous case, I do not see much to exploit about this knowledge, apart from the value potentially leading to a control variate (in a Gelfand and Dey 1996 spirit) and possibly to a stopping rule (by checking that the portion of the space visited so far has mass close to one, but this is more delicate than it sounds).
In a (possibly infinite) countable setting, it seems to me one gain (?) is that approximating expectations by Monte Carlo no longer requires iid simulations in the sense that once visited, atoms need not be visited again. Self-avoiding random walks and their generalisations thus appear as a natural substitute for MC(MC) methods in this setting, provided finding unexplored atoms proves manageable. For instance, a stopping rule is always available, namely that the cumulated weight of the visited fraction of the space is close enough to one. The above picture shows a toy example on a 500 x 500 grid with 0.1% of the mass remaining at the almost invisible white dots. (In my experiment, neighbours for the random exploration were chosen at random over the grid, as I assumed no global information was available about the repartition over the grid either of mass function or of the function whose expectation was seeked.)