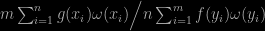[I wrote this set of comments right after MCqMC 2016 on a preliminary version of the paper so mileage may vary in terms of the adequation to the current version!]
In warp-U bridge sampling, newly arXived and first presented at MCqMC 16, Xiao-Li Meng continues (in collaboration with Lahzi Wang) his exploration of bridge sampling techniques towards improving the estimation of normalising constants and ratios thereof. The bridge sampling estimator of Meng and Wong (1996) is an harmonic mean importance sampler that requires iterations as it depends on the ratio of interest. Given that the normalising constant of a density does not depend on the chosen parameterisation in the sense that the Jacobian transform preserves this constant, a degree of freedom is in the choice of the parameterisation. This is the idea behind warp transformations. The initial version of Meng and Schilling (2002) used location-scale transforms, while the warp-U solution goes for a multiple location-scale transform that can be seen as based on a location-scale mixture representation of the target. With K components. This approach can also be seen as a sort of artificial reversible jump algorithm when one model is fully known. A strategy Nicolas and I also proposed in our nested sampling Biometrika paper.
Once such a mixture approximation is obtained. each and every component of the mixture can be turned into the standard version of the location-scale family by the appropriate location-scale transform. Since the component index k is unknown for a given X, they call this transform a random transform, which I find somewhat more confusing that helpful. The conditional distribution of the index given the observable x is well-known for mixtures and it is used here to weight the component-wise location-scale transforms of the original distribution p into something that looks rather similar to the standard version of the location-scale family. If no mode has been forgotten by the mixture. The simulations from the original p are then rescaled by one of those transforms, which index k is picked according to the conditional distribution. As explained later to me by XL, the random[ness] in the picture is due to the inclusion of a random ± sign. Still, in the notation introduced in (13), I do not get how the distribution Þ [sorry for using different symbols, I cannot render a tilde on a p] is defined since both ψ and W are random. Is it the marginal? In which case it would read as a weighted average of rescaled versions of p. I have the same problem with Theorem 1 in that I do not understand how one equates Þ with the joint distribution.
Equation (21) is much more illuminating (I find) than the previous explanation in that it exposes the fact that the principle is one of aiming at a new distribution for both the target and the importance function, with hopes that the fit will get better. It could have been better to avoid the notion of random transform, then, but this is mostly a matter of conveying the notion.
On more specifics points (or minutiae), the unboundedness of the likelihood is rarely if ever a problem when using EM. An alternative to the multiple start EM proposal would then be to get sequential and estimate the mixture in a sequential manner, only adding a component when it seems worth it. See eg Chopin and Pelgrin (2004) and Chopin (2007). This could also help with the bias mentioned therein since only a (tiny?) fraction of the data would be used. And the number of components K has an impact on the accuracy of the approximation, as in not missing a mode, and on the computing time. However my suggestion would be to avoid estimating K as this must be immensely costly.
Section 6 obviously relates to my folded Markov interests. If I understand correctly, the paper argues that the transformed density Þ does not need to be computed when considering the folding-move-unfolding step as a single step rather than three steps. I fear the description between equations (30) and (31) is missing the move step over the transformed space. Also on a personal basis I still do not see how to add this approach to our folding methodology, even though the different transforms act as as many replicas of the original Markov chain.
 Jackie Wong, Jon Forster (Warwick) and Peter Smith have just published a paper in Statistics & Computing on bridge sampling bias and improvement by splitting.
Jackie Wong, Jon Forster (Warwick) and Peter Smith have just published a paper in Statistics & Computing on bridge sampling bias and improvement by splitting.