Jackie Wong, Jon Forster (Warwick) and Peter Smith have just published a paper in Statistics & Computing on bridge sampling bias and improvement by splitting.
Jackie Wong, Jon Forster (Warwick) and Peter Smith have just published a paper in Statistics & Computing on bridge sampling bias and improvement by splitting.
“… known to be asymptotically unbiased, bridge sampling technique produces biased estimates in practical usage for small to moderate sample sizes (…) the estimator yields positive bias that worsens with increasing distance between the two distributions. The second type of bias arises when the approximation density is determined from the posterior samples using the method of moments, resulting in a systematic underestimation of the normalizing constant.”
Recall that bridge sampling is based on a double trick with two samples x and y from two (unnormalised) densities f and g that are interverted in a ratio
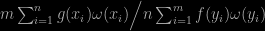
of unbiased estimators of the inverse normalising constants. Hence biased. The more the less similar these two densities are. Special cases for ω include importance sampling [unbiased] and reciprocal importance sampling. Since the optimal version of the bridge weight ω is the inverse of the mixture of f and g, it makes me wonder at the performance of using both samples top and bottom, since as an aggregated sample, they also come from the mixture, as in Owen & Zhou (2000) multiple importance sampler. However, a quick try with a positive Normal versus an Exponential with rate 2 does not show an improvement in using both samples top and bottom (even when using the perfectly normalised versions)
morc=(sum(f(y)/(nx*dnorm(y)+ny*dexp(y,2)))+
sum(f(x)/(nx*dnorm(x)+ny*dexp(x,2))))/(
sum(g(x)/(nx*dnorm(x)+ny*dexp(x,2)))+
sum(g(y)/(nx*dnorm(y)+ny*dexp(y,2))))
at least in terms of bias… Surprisingly (!) the bias almost vanishes for very different samples sizes either in favour of f or in favour of g. This may be a form of genuine defensive sampling, who knows?! At the very least, this ensures a finite variance for all weights. (The splitting approach introduced in the paper is a natural solution to create independence between the first sample and the second density. This reminded me of our two parallel chains in AMIS.)


 Feller et al., 2006")





![\mathbb{E}_\theta[g(X,\beta)]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Ctheta%5Bg%28X%2C%5Cbeta%29%5D%3D0&bg=000000&fg=B0B0B0&s=0&c=20201002)

![\mathbb{E}_\theta[g(X,\beta)]=0.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Ctheta%5Bg%28X%2C%5Cbeta%29%5D%3D0.&bg=000000&fg=B0B0B0&s=0&c=20201002)