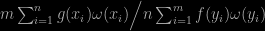Dennis Prangle signaled this paper during his talk of last week, first of our ABC ‘minars now rechristened as The One World ABC Seminar to join the “One World xxx Seminar” franchise! The paper is written by Thomas Müller and co-authors, all from Disney research [hence the illustration], and we discussed it in our internal reading seminar at Dauphine. The authors propose to parameterise the importance sampling density via neural networks, just like Dennis is using auto-encoders. Starting with the goal of approximating
Dennis Prangle signaled this paper during his talk of last week, first of our ABC ‘minars now rechristened as The One World ABC Seminar to join the “One World xxx Seminar” franchise! The paper is written by Thomas Müller and co-authors, all from Disney research [hence the illustration], and we discussed it in our internal reading seminar at Dauphine. The authors propose to parameterise the importance sampling density via neural networks, just like Dennis is using auto-encoders. Starting with the goal of approximating

(where they should assume f to be non-negative for the following), the authors aim at simulating from an approximation of f(x)/ℑ since this “ideal” pdf would give zero variance.
“Unfortunately, the above integral is often not solvable in closed form, necessitating its estimation with another Monte Carlo estimator.”
Among the discussed solutions, the Latent-Variable Model one is based on a pdf represented as a marginal. A mostly intractable integral, which the authors surprisingly seem to deem an issue as they do not mention the standard solution of simulating from the joint and using the conditional in the importance weight. (Or even more surprisingly and obviously wrongly see the latter as a biased approximation to the weight.)
“These “autoregressive flows” offer the desired exact evaluation of q(x;θ). Unfortunately, they generally only permit either efficient sample generation or efficient evaluation of q(x;θ), which makes them prohibitively expensive for our application to Mont Carlo integration.”
When presenting normalizing flows, namely the representation of the simulation output as the result of an invertible mapping of a standard (e.g., Gaussian or Uniform) random variable, x=h(u,θ), which can itself be decomposed into a composition of suchwise functions. And I am thus surprised this cannot be done in an efficient manner if transforms are well chosen…
“The key proposition of Dinh et al. (2014) is to focus on a specific class of mappings—referred to as coupling layers—that admit Jacobian matrices where determinants reduce to the product of diagonal terms.
Using a transform with a triangular Jacobian at each stage has the appeal of keeping the change of variable simple and allowing for non-linear transforms. Namely piecewise polynomials. When reading the one-blob (!) encoding , I am however uncertain the approach is more than the choice of a particular functional basis, as for instance wavelets (which may prove more costly to handle, granted!)
“Given that NICE scales well to high-dimensional problems…”
It is always unclear to me why almost every ML paper feels the urge to redefine & motivate the KL divergence. And to recall that it avoids bothering about the normalising constant. Looking at the variance of the MC estimator & seeking minimal values is praiseworthy, but only when the variance exists. What are the guarantees on the density estimate for this to happen? And where are the arguments for NICE scaling nicely to high dimensions? Interesting intrusion of path sampling, but is it of any use outside image analysis—I had forgotten Eric Veach’s original work was on light transport—?