 Over a lazy weekend, I watched the TV series The Frankenstein Chronicles, which I found quite remarkable (if definitely Gothic and possibly too gory for some!). Connections with celebrities of (roughly) the time abound: While Mary Shelley makes an appearance in the first season of the series, not only as the writer of the famous novel (already famous in the novel as well) but also as a participant to a deadly experiment that would succeed in the novel (and eventually in the series), Charles Dickens is a constant witness to the unraveling of scary events as Boz the journalist, somewhat running after the facts, William Blake dies in one of the early episodes after painting a series of tarot like cards that eventually explains it all, Ada Lovelace works on the robotic dual of Frankenstein, Robert Peel creates the first police force (which will be called the Bobbies after him!), John Snow’s uncovering of the cholera source as the pump of Broad Street is reinvented with more nefarious reasons, and possibly others. Besides these historical landmarks (!), the story revolves around the corpse trafficking that fed medical schools and plots for many a novel. The (true) Anatomy Act is about to pass to regulate body supply for anatomical purposes and ensues a debate on the end of God that permeates mostly the first season and just a little bit the second season, which is more about State versus Church… The series is not without shortcomings, in particular a rather disconnected plot (which has the appeal of being unpredictable of jumping from one genre to the next) and a repeated proneness of the main character to being a scapegoat, but the reconstitution of London at the time is definitely impressive (although I cannot vouch for its authenticity!). Only the last episode of Season 2 feels a bit short when delivering, by too conveniently tying up all loose threads.
Over a lazy weekend, I watched the TV series The Frankenstein Chronicles, which I found quite remarkable (if definitely Gothic and possibly too gory for some!). Connections with celebrities of (roughly) the time abound: While Mary Shelley makes an appearance in the first season of the series, not only as the writer of the famous novel (already famous in the novel as well) but also as a participant to a deadly experiment that would succeed in the novel (and eventually in the series), Charles Dickens is a constant witness to the unraveling of scary events as Boz the journalist, somewhat running after the facts, William Blake dies in one of the early episodes after painting a series of tarot like cards that eventually explains it all, Ada Lovelace works on the robotic dual of Frankenstein, Robert Peel creates the first police force (which will be called the Bobbies after him!), John Snow’s uncovering of the cholera source as the pump of Broad Street is reinvented with more nefarious reasons, and possibly others. Besides these historical landmarks (!), the story revolves around the corpse trafficking that fed medical schools and plots for many a novel. The (true) Anatomy Act is about to pass to regulate body supply for anatomical purposes and ensues a debate on the end of God that permeates mostly the first season and just a little bit the second season, which is more about State versus Church… The series is not without shortcomings, in particular a rather disconnected plot (which has the appeal of being unpredictable of jumping from one genre to the next) and a repeated proneness of the main character to being a scapegoat, but the reconstitution of London at the time is definitely impressive (although I cannot vouch for its authenticity!). Only the last episode of Season 2 feels a bit short when delivering, by too conveniently tying up all loose threads.
Archive for ABC in London
the Frankenstein chronicles
Posted in Statistics with tags ABC in London, Ada Lovelace, Anatomy Act, bobbies, Broad Street pump, Charles Dickens, Frankenstein, ghosts, gothic novels, horror, John Snow, Mary Shelley, Robert Peel, William Blake on March 31, 2019 by xi'ana Bayesian criterion for singular models [discussion]
Posted in Books, Statistics, University life with tags ABC in London, Bayesian principles, BIC, discussion paper, effective dimension, information criterion, judicial system, latex2wp, London, non-regular models, Ockham's razor, penalised likelihood, Read paper, Royal Statistical Society, sBIC, Series B, singular models on October 10, 2016 by xi'an [Here is the discussion Judith Rousseau and I wrote about the paper by Mathias Drton and Martyn Plummer, a Bayesian criterion for singular models, which was discussed last week at the Royal Statistical Society. There is still time to send a written discussion! Note: This post was written using the latex2wp converter.]
[Here is the discussion Judith Rousseau and I wrote about the paper by Mathias Drton and Martyn Plummer, a Bayesian criterion for singular models, which was discussed last week at the Royal Statistical Society. There is still time to send a written discussion! Note: This post was written using the latex2wp converter.]
It is a well-known fact that the BIC approximation of the marginal likelihood in a given irregular model 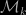
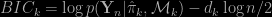
where 
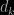

A way to understand the behaviour of 
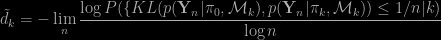
when it exists, see for instance the discussions in Chambaz and Rousseau (2008) and Rousseau (2007). Watanabe (2009} provided a more precise formula, which is the starting point of the approach of Drton and Plummer:
![\displaystyle \log m(\mathbf Y_n |\mathcal M_k) = \log p(\mathbf Y_n| \hat \pi_k, \mathcal M_k) - \lambda_k(\pi_0) \log n + [m_k(\pi_0) - 1] \log \log n + O_p(1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clog+m%28%5Cmathbf+Y_n+%7C%5Cmathcal+M_k%29+%3D+%5Clog+p%28%5Cmathbf+Y_n%7C+%5Chat+%5Cpi_k%2C+%5Cmathcal+M_k%29+-+%5Clambda_k%28%5Cpi_0%29+%5Clog+n+%2B+%5Bm_k%28%5Cpi_0%29+-+1%5D+%5Clog+%5Clog+n+%2B+O_p%281%29&bg=000000&fg=B0B0B0&s=0&c=20201002)
where 

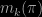
1. Why do we want to use a BIC type formula?
The BIC formula can be viewed from a purely frequentist perspective, as an example of penalised likelihood. The difficulty then stands into choosing the penalty and a common view on these approaches is to choose the smallest possible penalty that still leads to consistency of the model choice procedure, since it then enjoys better separation rates. In this case a 


2. Should we care so much about penalized or marginal likelihoods ?
Marginal or penalized likelihoods are exploratory tools in a statistical analysis, as one is trying to define a reasonable model to fit the data. An unpleasant feature of these tools is that they provide numbers which in themselves do not have much meaning and can only be used in comparison with others and without any notion of uncertainty attached to them. A somewhat richer approach of exploratory analysis is to interrogate the posterior distributions by either varying the priors or by varying the loss functions. The former has been proposed in van Havre et l. (2016) in mixture models using the prior tempering algorithm. The latter has been used for instance by Yau and Holmes (2013) for segmentation based on Hidden Markov models. Introducing a decision-analytic perspective in the construction of information criteria sounds to us like a reasonable requirement, especially when accounting for the current surge in studies of such aspects.
[Posted as arXiv:1610.02503]
approximate Bayesian inference
Posted in Books, pictures, Statistics, Travel, University life with tags ABC in London, alive particle filter, Bayesian Analysis, Dirichlet prior, empirical likelihood, expectation-propagation, integer time-series, pMCMC, pseudo-marginal MCMC on March 23, 2016 by xi'anMaybe it is just a coincidence, but both most recent issues of Bayesian Analysis have an article featuring approximate Bayesian inference. One is by Daniel Add Contact Form Graham and co-authors on Approximate Bayesian Inference for Doubly Robust Estimation, while the other one is by Chris Drovandi and co-authors from QUT on Exact and Approximate Bayesian Inference for Low Integer-Valued Time Series Models with Intractable Likelihoods. The first paper has little connection with ABC. Even though it (a) uses a lot of three letter acronyms [which does not help with speed reading] and (b) relies on moment based and propensity score models. Instead, it relies on Bayesian bootstrap, which suddenly seems to me to be rather connected with empirical likelihood! Except the weights are estimated via a Dirichlet prior instead of being optimised. The approximation lies in using the bootstrap to derive a posterior predictive. I did not spot any assessment or control of the approximation effect in the paper.
“Note that we are always using the full data so avoiding the need to choose a summary statistic” (p.326)

The second paper connects pMCMC with ABC. Plus pseudo-marginals on the side! And even simplified reversible jump MCMC!!! I am far from certain I got every point of the paper, though, especially the notion of dimension reduction associated with this version of reversible jump MCMC. It may mean that latent variables are integrated out in approximate (marginalised) likelihoods [as explicated in Andrieu and Roberts (2009)].
“The difference with the common ABC approach is that we match on observations one-at-a-time” (p.328)
The model that the authors study is an integer value time-series, like the INAR(p) model. Which integer support allows for a non-zero probability of exact matching between simulated and observed data. One-at-a-time as indicated in the above quote. And integer valued tolerances like ε=1 otherwise. In the case auxiliary variables are necessary, the authors resort to the alive particle filter of Jasra et al. (2013), which main point is to produce an unbiased estimate of the (possibly approximate) likelihood, to be exploited by pseudo-marginal techniques. However, unbiasedness sounds less compelling when moving to approximate methods, as illustrated by the subsequent suggestion to use a more stable estimate of the log-likelihood. In fact, when the tolerance ε is positive, the pMCMC acceptance probability looks quite close to an ABC-MCMC probability when relying on several pseudo-data simulations. Which is unbiased for the “right” approximate target. A fact that may actually holds for all ABC algorithms. One quite interesting aspect of the paper is its reflection about the advantage of pseudo-marginal techniques for RJMCMC algorithms since they allow for trans-dimension moves to be simplified, as they consider marginals on the space of interest. Up to this day, I had not realised Andrieu and Roberts (2009) had a section on this aspect… I am still unclear about the derivation of the posterior probabilities of the models under comparison, unless it is a byproduct of the RJMCMC algorithm. A last point is that, for some of the Markov models used in the paper, the pseudo observations can be produced as a random one-time move away from the current true observation, which makes life much easier for ABC and explain why exact simulations can sometimes be produced. (A side note: the authors mention on p.326 that EP is only applicable when the posterior is from an exponential family, while my understanding is that it uses an exponential family to approximate the true posterior.)
ABC in Sydney, July 3-4, 2014!!!
Posted in pictures, Statistics, Travel, University life, Wines with tags ABC, ABC in London, ABC in Paris, ABC in Rome, abc-in-sydney, Australia, Cancún, IMS, ISBA, simulation, Sydney, Sydney Harbour, Sydney Opera, UNSW, workshop on February 12, 2014 by xi'an After ABC in Paris in 2009, ABC in London in 2011, and ABC in Roma last year, things are accelerating since there will be—as I just learned— an ABC in Sydney next July (not June as I originally typed, thanks Robin!). The workshop on the current developments of ABC methodology thus leaves Europe to go down-under and to take advantage of the IMS Meeting in Sydney on July 7-10, 2014. Hopefully, “ABC in…” will continue its tour of European capitals in 2015! To keep up with an unbroken sequence of free workshops, Scott Sisson has managed to find support so that attendance is free of charge (free as in “no registration fee at all”!) but you do need to register as space is limited. While I would love to visit UNSW and Sydney once again and attend the workshop, I will not, getting ready for Cancún and our ABC short course there.
After ABC in Paris in 2009, ABC in London in 2011, and ABC in Roma last year, things are accelerating since there will be—as I just learned— an ABC in Sydney next July (not June as I originally typed, thanks Robin!). The workshop on the current developments of ABC methodology thus leaves Europe to go down-under and to take advantage of the IMS Meeting in Sydney on July 7-10, 2014. Hopefully, “ABC in…” will continue its tour of European capitals in 2015! To keep up with an unbroken sequence of free workshops, Scott Sisson has managed to find support so that attendance is free of charge (free as in “no registration fee at all”!) but you do need to register as space is limited. While I would love to visit UNSW and Sydney once again and attend the workshop, I will not, getting ready for Cancún and our ABC short course there.
fie on fee frenzy!
Posted in Mountains, Statistics, Travel, University life with tags ABC in London, ABC in Paris, ABC in Rome, Bayes 250, Bayesian conference, Bayesian statistics, Duke University, Durham, London, MCMSki IV, O-Bayes 2013, RSS, Thomas Bayes on June 11, 2013 by xi'an In the past years, I noticed a clear inflation on conference fees, inflation that I feel unjustified… I already mentioned the huge $720 fees for the Winter Simulation Conference (WSC 2012), which were certainly not all due to the heating bill! Even conferences held by and in universities or societies seem to face the same doom: to stick to conferences I will attend—and do support, to the point of being directly or indirectly involved—, take for instance Bayes 250 in London (RSS Headquarters), £135, Bayes 250 at Duke, $190, both one day-long, and O-Bayes 2013, also at Duke, $480 (in par with JSM fees)… While those later conferences include side “benefits” like meals and banquet, the amount remains large absolutive. Too large. And prohibitive for participants from less-favoured countries (possibly including speakers themselves in the case of O-Bayes 2013). And also counter-productive in the case of both Bayes 250 conferences since we want to get together to celebrate two and a half centuries of Bayesian statistics. Since most of the talks there will be partly commemorative, rather than on the brink of research, I fear some people may have to make a choice to allocate their meagre research funds to other conferences. And I do not understand why universities now consider organising meetings as a source of income rather than as a natural part of their goals.
In the past years, I noticed a clear inflation on conference fees, inflation that I feel unjustified… I already mentioned the huge $720 fees for the Winter Simulation Conference (WSC 2012), which were certainly not all due to the heating bill! Even conferences held by and in universities or societies seem to face the same doom: to stick to conferences I will attend—and do support, to the point of being directly or indirectly involved—, take for instance Bayes 250 in London (RSS Headquarters), £135, Bayes 250 at Duke, $190, both one day-long, and O-Bayes 2013, also at Duke, $480 (in par with JSM fees)… While those later conferences include side “benefits” like meals and banquet, the amount remains large absolutive. Too large. And prohibitive for participants from less-favoured countries (possibly including speakers themselves in the case of O-Bayes 2013). And also counter-productive in the case of both Bayes 250 conferences since we want to get together to celebrate two and a half centuries of Bayesian statistics. Since most of the talks there will be partly commemorative, rather than on the brink of research, I fear some people may have to make a choice to allocate their meagre research funds to other conferences. And I do not understand why universities now consider organising meetings as a source of income rather than as a natural part of their goals.
Now, you may ask, and what about MCMski on which I have more than a modicum of control..?! Well, the sole cost there is renting the conference centre in Chamonix, which is the only place I knew where a large conference could be held. Apart from that, no frill! The coffee breaks will be few and frugal, there will be no free lunch or breakfast or banquet, and no one will get a free entry or a paid invitation. As a result, the registration fee is only 170€ for three days (plus a free satellite meeting the next day), an amount computed on an expected number of participants of 150 and which could lead me to pay the deficit from my own research grants in case I am wrong. (And may I recall the “ABC in…” series, which has been free of fees so far!)
My point, overall, is that we should aim at more frugal meetings, in order to attract larger and more diverse crowds (even though fees are only part of the equation, lodging and travelling can be managed to some extent as long as the workshop is not in too an exotic location).
