 Tamara Polajnar") In connection with the official launch of the Alan Turing Institute (or ATI, of which Warwick is a partner), it funded an ATI Scoping workshop
In connection with the official launch of the Alan Turing Institute (or ATI, of which Warwick is a partner), it funded an ATI Scoping workshop yesterday a week ago in Warwick around the notion(s) of intractable likelihood(s) and how this could/should fit within the themes of the Institute [hence the scoping]. This is one among many such scoping workshops taking place at all partners, as reported on the ATI website. Workshop that was quite relaxed and great fun, if only for getting together with most people (and friends) in the UK interested in the topic. But also pointing out some new themes I had not previously though of as related to ilike. For instance, questioning the relevance of likelihood for inference and putting forward decision theory under model misspecification, connecting with privacy and ethics [hence making intractable “good”!], introducing uncertain likelihood, getting more into network models, RKHS as a natural summary statistic, swarm of solutions for consensus inference… (And thanks to Mark Girolami for this homage to the iconic LP of the Sex Pistols!, that I played maniacally all over 1978…) My own two-cents into the discussion were mostly variations of other discussions, borrowing from ABC (and ABC slides) to call for a novel approach to approximate inference:
Archive for consensus
intractable likelihoods (even) for Alan
Posted in Kids, pictures, Statistics with tags ABC, Alan Turing Institute, consensus, decision theory, intractable likelihood, likelihood function, misspecified model, network, privacy, RKHS, Sex Pistols, summary statistics, University of Warwick on November 19, 2015 by xi'anMoment conditions and Bayesian nonparametrics
Posted in R, Statistics, University life with tags Bayesian nonparametrics, consensus, econometrics, Gibbs sampling, Hausdorff metric, Jacobian, Jeffreys priors, Lebesgue measure, manifold, method of moments, zero measure set on August 6, 2015 by xi'an Luke Bornn, Neil Shephard, and Reza Solgi (all from Harvard) have arXived a pretty interesting paper on simulating targets on a zero measure set. Although it is not initially presented this way, but rather in non-parametric terms as moment conditions
Luke Bornn, Neil Shephard, and Reza Solgi (all from Harvard) have arXived a pretty interesting paper on simulating targets on a zero measure set. Although it is not initially presented this way, but rather in non-parametric terms as moment conditions
![\mathbb{E}_\theta[g(X,\beta)]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Ctheta%5Bg%28X%2C%5Cbeta%29%5D%3D0&bg=000000&fg=B0B0B0&s=0&c=20201002)
where θ is the parameter of the sampling distribution, constrained by the value of β. (Which also contains quantile regression.) The very problem of simulating under a hard constraint has been bugging me for years and it is hence very exciting to see them come up with a proposal towards solving this difficulty! Even though it is restricted here to observations with a finite support (hence allowing for the use of a parametric Dirichlet prior). One interesting extension (Section 3.6) processed in the paper is the case when the support is unknown, but finite, with some points in the support being unobserved. Maybe connecting with non-parametrics if a prior is added on the number of unobserved points.
The setting of constricting θ via a parameterised moment condition relates to moment defined econometrics models, in a similar spirit to Gallant’s paper I recently discussed, but equally to empirical likelihood, which would then benefit from a fully Bayesian treatment thanks to the approach advocated by the authors.
 Despite the zero-measure difficulty, or more exactly the non-linear manifold structure of the parameter space, for instance
Despite the zero-measure difficulty, or more exactly the non-linear manifold structure of the parameter space, for instance
β = log {θ/(1-θ)}
the authors manage to define a “projected” [my words] measure on the set of admissible pairs (β,θ). In a sense this is related with the choice of a certain metric, but the so-called Hausdorff reference measure allows for an automated definition of the original prior. It took me a (wee) while to spot (p.7) that the starting point was not a (unconstrained) prior on that (unconstrained) pair (β,θ) but directly on the manifold
![\mathbb{E}_\theta[g(X,\beta)]=0.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Ctheta%5Bg%28X%2C%5Cbeta%29%5D%3D0.&bg=000000&fg=B0B0B0&s=0&c=20201002)
Which makes its construction a difficulty. Even though, as noted in Section 4, all that we need is a prior over θ since the Hausdorff-Jacobian identity defines the “joint”, in a sort of backward way. (This is a wee bit confusing in that β being a transform of θ, all we need is a prior over θ, but we nonetheless end up with a different density on the joint distribution on the pair (β,θ). Any connection with incompatible priors merged together into a consensus prior?) Another question extending the scope of the paper would be to define Jeffreys’ or reference priors in this manifold sense.
The authors also discuss (Section 4.3) the problem I originally thought they were processing, namely starting from an unconstrained pair (β,θ) and it corresponding prior. The projected prior can then be defined based on a version of the original density on the constrained space, but it is definitely arbitrary. In that sense the paper does not address the general problem.
“…traditional simulation algorithms will fail because the prior and the posterior of the model are supported on a zero Lebesgue measure set…” (p.10)

I somewhat resist this presentation through the measure zero set: once the prior is defined on a manifold, the fact that it is a measure zero set in a larger space is moot. Provided one can simulate a proposal over that manifold, e.g., a random walk, absolutely continuous wrt the same dominating measure, and compute or estimate a Metropolis-Hastings ratio of densities against a common measure, one can formally run MCMC on manifolds as well as regular Euclidean spaces. A first and theoretically straightforward (?) solution is to solve the constraint
in β=β(θ). Then the joint prior p(β,θ) can be projected by the Hausdorff projection into p(θ). For instance, in the case of the above logit transform, the projected density is
p(θ)=p(β,θ) {1+1/θ²(1-θ)²}½
In practice, the inversion may be too costly and Bornn et al. directly simulate the pair (β,θ) within the manifold capitalising on the fact that the constraint is linear in θ given β. Indeed, in this setting, β is unconstrained and θ can be simulated from a proposal restricted to the hyperplane. Gibbs-like.
where did the normalising constants go?! [part 2]
Posted in R, Statistics, Travel with tags beta distribution, big data, consensus, embarassingly parallel, importance sampling, normalising constant, parallel processing, R on March 12, 2014 by xi'an Coming (swiftly and smoothly) back home after this wonderful and intense week in Banff, I hugged my loved ones, quickly unpacked, ran a washing machine, and then sat down to check where and how my reasoning was wrong. To start with, I experimented with a toy example in R:
Coming (swiftly and smoothly) back home after this wonderful and intense week in Banff, I hugged my loved ones, quickly unpacked, ran a washing machine, and then sat down to check where and how my reasoning was wrong. To start with, I experimented with a toy example in R:
# true target is (x^.7(1-x)^.3) (x^1.3 (1-x)^1.7) # ie a Beta(3,3) distribution # samples from partial posteriors N=10^5 sam1=rbeta(N,1.7,1.3) sam2=rbeta(N,2.3,2.7) # first version: product of density estimates dens1=density(sam1,from=0,to=1) dens2=density(sam2,from=0,to=1) prod=dens1$y*dens2$y # normalising by hand prod=prod*length(dens1$x)/sum(prod) plot(dens1$x,prod,type="l",col="steelblue",lwd=2) curve(dbeta(x,3,3),add=TRUE,col="sienna",lty=3,lwd=2) # second version: F-S & P's yin+yang sampling # with weights proportional to the other posterior subsam1=sam1[sample(1:N,N,prob=dbeta(sam1,2.3,2.7),rep=T)] plot(density(subsam1,from=0,to=1),col="steelblue",lwd=2) curve(dbeta(x,3,3),add=T,col="sienna",lty=3,lwd=2) subsam2=sam2[sample(1:N,N,prob=dbeta(sam2,1.7,1.3),rep=T)] plot(density(subsam2,from=0,to=1),col="steelblue",lwd=2) curve(dbeta(x,3,3),add=T,col="sienna",lty=3,lwd=2)
and (of course!) it produced the perfect fits reproduced below. Writing the R code acted as a developing bath as it showed why we could do without the constants!
 “Of course”, because the various derivations in the above R code all are clearly independent from the normalising constant: (i) when considering a product of kernel density estimators, as in the first version, this is an approximation of
“Of course”, because the various derivations in the above R code all are clearly independent from the normalising constant: (i) when considering a product of kernel density estimators, as in the first version, this is an approximation of

as well as of
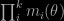
since the constant does not matter. (ii) When considering a sample from mi and weighting it by the product of the remaining true or estimated mj‘s, this is a sampling weighting resampling simulation from the density proportional to the product and hence, once again, the constants do not matter. At last, (iii) when mixing the two subsamples, since they both are distributed from the product density, the constants do not matter. As I slowly realised when running this morning (trail-running, not code-runninh!, for the very first time in ten days!), the straight-from-the-box importance sampling version on the mixed samples I considered yesterday (to the point of wondering out loud where did the constants go) is never implemented in the cited papers. Hence, the fact that

is enough to justify handling the target directly as the product of the partial marginals. End of the mystery. Anticlimactic end, sorry…
where did the normalising constants go?! [part 1]
Posted in R, Statistics, Travel with tags big data, consensus, embarassingly parallel, normalising constant, parallel processing on March 11, 2014 by xi'anWhen listening this week to several talks in Banff handling large datasets or complex likelihoods by parallelisation, splitting the posterior as
and handling each term of this product on a separate processor or thread as proportional to a probability density,

then producing simulations from the mi‘s and attempting at deriving simulations from the original product, I started to wonder where all those normalising constants went. What vaguely bothered me for a while, even prior to the meeting, and then unclicked thanks to Sylvia’s talk yesterday was the handling of the normalising constants ωi by those different approaches… Indeed, it seemed to me that the samples from the mi‘s should be weighted by
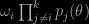
rather than just

or than the product of the other posteriors
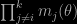
which makes or should make a significant difference. For instance, a sheer importance sampling argument for the aggregated sample exhibited those weights
![\mathbb{E}[h(\theta_i)\prod_{i=1}^k p_i(\theta_i)\big/m_i(\theta_i)]=\omega_i^{-1}\int h(\theta_i)\prod_{j}^k p_j(\theta_i)\text{d}\theta_i](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bh%28%5Ctheta_i%29%5Cprod_%7Bi%3D1%7D%5Ek+p_i%28%5Ctheta_i%29%5Cbig%2Fm_i%28%5Ctheta_i%29%5D%3D%5Comega_i%5E%7B-1%7D%5Cint+h%28%5Ctheta_i%29%5Cprod_%7Bj%7D%5Ek+p_j%28%5Ctheta_i%29%5Ctext%7Bd%7D%5Ctheta_i&bg=000000&fg=B0B0B0&s=0&c=20201002)
Hence processing the samples on an equal footing or as if the proper weight was the product of the other posteriors mj should have produced a bias in the resulting sample. This was however the approach in both Scott et al.‘s and Neiswanger et al.‘s perspectives. As well as Wang and Dunson‘s, who also started from the product of posteriors. (Normalizing constants are considered in, e.g., Theorem 1, but only for the product density and its Weierstrass convolution version.) And in Sylvia’s talk. Such a consensus of high calibre researchers cannot get it wrong! So I must have missed something: what happened is that the constants eventually did not matter, as expanded in the next post…
