This recent arXival by Song and Kingma covers different computational approaches to semi-parametric estimation, but also exposes imho the chasm existing between statistical and machine learning perspectives on the problem.
“Energy-based models are much less restrictive in functional form: instead of specifying a normalized probability, they only specify the unnormalized negative log-probability (…) Since the energy function does not need to integrate to one, it can be parameterized with any nonlinear regression function.”
The above in the introduction appears first as a strange argument, since the mass one constraint is the least of the problems when addressing non-parametric density estimation. Problems like the convergence, the speed of convergence, the computational cost and the overall integrability of the estimator. It seems however that the restriction or lack thereof is to be understood as the ability to use much more elaborate forms of densities, which are then black-boxes whose components have little relevance… When using such mega-over-parameterised representations of densities, such as neural networks and normalising flows, a statistical assessment leads to highly challenging questions. But convergence (in the sample size) does not appear to be a concern for the paper. (Except for a citation of Hyvärinen on p.5.)
Using MLE in this context appears to be questionable, though, since the base parameter θ is not unlikely to remain identifiable. Computing the MLE is therefore a minor issue, in this regard, a resolution based on simulated gradients being well-chartered from the earlier era of stochastic optimisation as in Robbins & Monro (1954), Duflo (1996) or Benveniste & al. (1990). (The log-gradient of the normalising constant being estimated by the opposite of the gradient of the energy at a random point.)
“Running MCMC till convergence to obtain a sample x∼p(x) can be computationally expensive.”
Contrastive divergence à la Hinton (2002) is presented as a solution to the convergence problem by stopping early, which seems reasonable given the random gradient is mostly noise. With a possible correction for bias à la Jacob & al. (missing the published version).
An alternative to MLE is the 2005 Hyvärinen score, notorious for bypassing the normalising constant. But blamed in the paper for being costly in the dimension d of the variate x, due to the second derivative matrix. Which can be avoided by using Stein’s unbiased estimator of the risk (yay!) if using randomized data. And surprisingly linked with contrastive divergence as well, if a Taylor expansion is good enough an approximation! An interesting byproduct of the discussion on score matching is to turn it into an unintended form of ABC!
“Many methods have been proposed to automatically tune the noise distribution, such as Adversarial Contrastive Estimation (Bose et al., 2018), Conditional NCE (Ceylan and Gutmann, 2018) and Flow Contrastive Estimation (Gao et al., 2020).”
A third approach is the noise contrastive estimation method of Gutmann & Hyvärinen (2010) that connects with both others. And is a precursor of GAN methods, mentioned at the end of the paper via a (sort of) variational inequality.


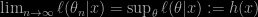
 While having breakfast (after an early morn swim at the vintage La Butte aux Cailles pool, which let me in free!), I noticed a
While having breakfast (after an early morn swim at the vintage La Butte aux Cailles pool, which let me in free!), I noticed a 