 George Karabatsos and Fabrizio Leisen have recently published in Statistics Surveys a fairly complete survey on ABC methods [which earlier arXival I had missed]. Listing within an extensive bibliography of 20 pages some twenty-plus earlier reviews on ABC (with further ones in applied domains)!
George Karabatsos and Fabrizio Leisen have recently published in Statistics Surveys a fairly complete survey on ABC methods [which earlier arXival I had missed]. Listing within an extensive bibliography of 20 pages some twenty-plus earlier reviews on ABC (with further ones in applied domains)!
“(…) any ABC method (algorithm) can be categorized as either (1) rejection-, (2) kernel-, and (3) coupled ABC; and (4) synthetic-, (5) empirical- and (6) bootstrap-likelihood methods; and can be combined with classical MC or VI algorithms [and] all 22 reviews of ABC methods have covered rejection and kernel ABC methods, but only three covered synthetic likelihood, one reviewed the empirical likelihood, and none have reviewed coupled ABC and bootstrap likelihood methods.”
The motivation for using approximate likelihood methods is provided by the examples of g-and-k distributions, although the likelihood can be efficiently derived by numerical means, as shown by Pierre Jacob‘s winference package, of mixed effect linear models, although a completion by the mixed effects themselves is available for Gibbs sampling as in Zeger and Karim (1991), and of the hidden Potts model, which we covered by pre-processing in our 2015 paper with Matt Moores, Chris Drovandi, Kerrie Mengersen. The paper produces a general representation of the approximate likelihood that covers the algorithms listed above as through the table below (where t(.) denotes the summary statistic):
 The table looks a wee bit challenging simply because the review includes the synthetic likelihood approach of Wood (2010), which figured preeminently in the 2012 Read Paper discussion but opens the door to all kinds of approximations of the likelihood function, including variational Bayes and non-parametric versions. After a description of the above versions (including a rather ignored coupled version) and the special issue of ABC model choice, the authors expand on the difficulties with running ABC, from multiple tuning issues, to the genuine curse of dimensionality in the parameter (with unnecessary remarks on low-dimension sufficient statistics since they are almost surely inexistent in most realistic settings), to the mis-specified case (on which we are currently working with David Frazier and Judith Rousseau). To conclude, an worthwhile update on ABC and on the side a funny typo from the reference list!
The table looks a wee bit challenging simply because the review includes the synthetic likelihood approach of Wood (2010), which figured preeminently in the 2012 Read Paper discussion but opens the door to all kinds of approximations of the likelihood function, including variational Bayes and non-parametric versions. After a description of the above versions (including a rather ignored coupled version) and the special issue of ABC model choice, the authors expand on the difficulties with running ABC, from multiple tuning issues, to the genuine curse of dimensionality in the parameter (with unnecessary remarks on low-dimension sufficient statistics since they are almost surely inexistent in most realistic settings), to the mis-specified case (on which we are currently working with David Frazier and Judith Rousseau). To conclude, an worthwhile update on ABC and on the side a funny typo from the reference list!
Li, W. and Fearnhead, P. (2018, in press). On the asymptotic efficiency
of approximate Bayesian computation estimators. Biometrika na na-na.




")
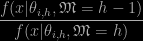
 is the model index,
is the model index, ‘s are simulated from the posterior under model h,
‘s are simulated from the posterior under model h, only considers the h-1 first components of
only considers the h-1 first components of 