 Dennis Prangle released last week an R package called gk and an associated arXived paper for running inference on the g-and-k and g-and-h quantile distributions. As should be clear from an earlier review on Karian’s and Dudewicz’s book quantile distributions, I am not particularly fond of those distributions which construction seems very artificial to me, as mostly based on the production of a closed-form quantile function. But I agree they provide a neat benchmark for ABC methods, if nothing else. However, as recently pointed out in our Wasserstein paper with Espen Bernton, Pierre Jacob and Mathieu Gerber, and explained in a post of Pierre’s on Statisfaction, the pdf can be easily constructed by numerical means, hence allows for an MCMC resolution, which is also a point made by Dennis in his paper. Using the closed-form derivation of the Normal form of the distribution [i.e., applied to Φ(x)] so that numerical derivation is not necessary.
Dennis Prangle released last week an R package called gk and an associated arXived paper for running inference on the g-and-k and g-and-h quantile distributions. As should be clear from an earlier review on Karian’s and Dudewicz’s book quantile distributions, I am not particularly fond of those distributions which construction seems very artificial to me, as mostly based on the production of a closed-form quantile function. But I agree they provide a neat benchmark for ABC methods, if nothing else. However, as recently pointed out in our Wasserstein paper with Espen Bernton, Pierre Jacob and Mathieu Gerber, and explained in a post of Pierre’s on Statisfaction, the pdf can be easily constructed by numerical means, hence allows for an MCMC resolution, which is also a point made by Dennis in his paper. Using the closed-form derivation of the Normal form of the distribution [i.e., applied to Φ(x)] so that numerical derivation is not necessary.
Archive for quantile distribution
g-and-k [or -h] distributions
Posted in Statistics with tags ABC, ABC de Sevilla, benchmark, Dennis Prangle, g-and-k distributions, MCMC, numerical derivation, numerical integration, quantile distribution, Wasserstein distance on July 17, 2017 by xi'anextending ABC to high dimensions via Gaussian copula
Posted in Books, pictures, Statistics, Travel, Uncategorized, University life with tags ABC, copulas, population Monte Carlo, quantile distribution on April 28, 2015 by xi'an Li, Nott, Fan, and Sisson arXived last week a new paper on ABC methodology that I read on my way to Warwick this morning. The central idea in the paper is (i) to estimate marginal posterior densities for the components of the model parameter by non-parametric means; and (ii) to consider all pairs of components to deduce the correlation matrix R of the Gaussian (pdf) transform of the pairwise rank statistic. From those two low-dimensional estimates, the authors derive a joint Gaussian-copula distribution by using inverse pdf transforms and the correlation matrix R, to end up with a meta-Gaussian representation
Li, Nott, Fan, and Sisson arXived last week a new paper on ABC methodology that I read on my way to Warwick this morning. The central idea in the paper is (i) to estimate marginal posterior densities for the components of the model parameter by non-parametric means; and (ii) to consider all pairs of components to deduce the correlation matrix R of the Gaussian (pdf) transform of the pairwise rank statistic. From those two low-dimensional estimates, the authors derive a joint Gaussian-copula distribution by using inverse pdf transforms and the correlation matrix R, to end up with a meta-Gaussian representation

where the η’s are the Gaussian transforms of the inverse-cdf transforms of the θ’s,that is,

Or rather

given that the g’s are estimated.
This is obviously an approximation of the joint in that, even in the most favourable case when the g’s are perfectly estimated, and thus the components perfectly Gaussian, the joint is not necessarily Gaussian… But it sounds quite interesting, provided the cost of running all those transforms is not overwhelming. For instance, if the g’s are kernel density estimators, they involve sums of possibly a large number of terms.
One thing that bothers me in the approach, albeit mostly at a conceptual level for I realise the practical appeal is the use of different summary statistics for approximating different uni- and bi-dimensional marginals. This makes for an incoherent joint distribution, again at a conceptual level as I do not see immediate practical consequences… Those local summaries also have to be identified, component by component, which adds another level of computational cost to the approach, even when using a semi-automatic approach as in Fernhead and Prangle (2012). Although the whole algorithm relies on a single reference table.
The examples in the paper are (i) the banana shaped “Gaussian” distribution of Haario et al. (1999) that we used in our PMC papers, with a twist; and (ii) a g-and-k quantile distribution. The twist in the banana (!) is that the banana distribution is the prior associated with the mean of a Gaussian observation. In that case, the meta-Gaussian representation seems to hold almost perfectly, even in p=50 dimensions. (If I remember correctly, the hard part in analysing the banana distribution was reaching the tails, which are extremely elongated in at least one direction.) For the g-and-k quantile distribution, the same holds, even for a regular ABC. What seems to be of further interest would be to exhibit examples where the meta-Gaussian is clearly an approximation. If such cases exist.
Approximate Integrated Likelihood via ABC methods
Posted in Books, Statistics, University life with tags ABC, Bayesian asymptotics, kernel density estimator, marginalisation, marginalisation paradoxes, nuisance parameters, quantile distribution, semi-parametrics, simulation on March 13, 2014 by xi'anMy PhD student Clara Grazian just arXived this joint work with Brunero Liseo on using ABC for marginal density estimation. The idea in this paper is to produce an integrated likelihood approximation in intractable problems via the ratio
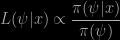
both terms in the ratio being estimated from simulations,

(with possible closed form for the denominator). Although most of the examples processed in the paper (Poisson means ratio, Neyman-Scott’s problem, g-&-k quantile distribution, semi-parametric regression) rely on summary statistics, hence de facto replacing the numerator above with a pseudo-posterior conditional on those summaries, the approximation remains accurate (for those examples). In the g-&-k quantile example, Clara and Brunero compare our ABC-MCMC algorithm with the one of Allingham et al. (2009, Statistics & Computing): the later does better by not replicating values in the Markov chain but instead proposing a new value until it is accepted by the usual Metropolis step. (Although I did not spend much time on this issue, I cannot see how both approaches could be simultaneously correct. Even though the outcomes do not look very different.) As noted by the authors, “the main drawback of the present approach is that it requires the use of proper priors”, unless the marginalisation of the prior can be done analytically. (This is an interesting computational problem: how to provide an efficient approximation to a marginal density of a σ-finite measure, assuming this density exists.)
Clara will give a talk at CREST-ENSAE today about this work, in the Bayes in Paris seminar: 2pm in room 18.
ABC+EL=no D(ata)
Posted in Books, pictures, R, Statistics, University life with tags ABC, ABCel, ARCH model, GARCH model, Kingman's coalescent, Monte Carlo Statistical Methods, O'Bayes 2011, PNAS, population genetics, quantile distribution, Shanghai, simulation, tseries on May 28, 2012 by xi'an It took us a loooong while [for various and uninteresting reasons] but we finally ended up completing a paper on ABC using empirical likelihood (EL) that was started by me listening to Brunero Liseo’s tutorial in O’Bayes-2011 in Shanghai… Brunero mentioned empirical likelihood as a semi-parametric technique w/o much Bayesian connections and this got me thinking of a possible recycling within ABC. I won’t get into the details of empirical likelihood, referring to Art Owen’s book “Empirical Likelihood” for a comprehensive entry, The core idea of empirical likelihood is to use a maximum entropy discrete distribution supported by the data and constrained by estimating equations related with the parameters of interest/of the model. As such, it is a non-parametric approach in the sense that the distribution of the data does not need to be specified, only some of its characteristics. Econometricians have been quite busy at developing this kind of approach over the years, see e.g. Gouriéroux and Monfort’s Simulation-Based Econometric Methods). However, this empirical likelihood technique can also be seen as a convergent approximation to the likelihood and hence exploited in cases when the exact likelihood cannot be derived. For instance, as a substitute to the exact likelihood in Bayes’ formula. Here is for instance a comparison of a true normal-normal posterior with a sample of 10³ points simulated using the empirical likelihood based on the moment constraint.
It took us a loooong while [for various and uninteresting reasons] but we finally ended up completing a paper on ABC using empirical likelihood (EL) that was started by me listening to Brunero Liseo’s tutorial in O’Bayes-2011 in Shanghai… Brunero mentioned empirical likelihood as a semi-parametric technique w/o much Bayesian connections and this got me thinking of a possible recycling within ABC. I won’t get into the details of empirical likelihood, referring to Art Owen’s book “Empirical Likelihood” for a comprehensive entry, The core idea of empirical likelihood is to use a maximum entropy discrete distribution supported by the data and constrained by estimating equations related with the parameters of interest/of the model. As such, it is a non-parametric approach in the sense that the distribution of the data does not need to be specified, only some of its characteristics. Econometricians have been quite busy at developing this kind of approach over the years, see e.g. Gouriéroux and Monfort’s Simulation-Based Econometric Methods). However, this empirical likelihood technique can also be seen as a convergent approximation to the likelihood and hence exploited in cases when the exact likelihood cannot be derived. For instance, as a substitute to the exact likelihood in Bayes’ formula. Here is for instance a comparison of a true normal-normal posterior with a sample of 10³ points simulated using the empirical likelihood based on the moment constraint.
 Mengersen, Pudlo, and Robert, May 2012")
The paper we wrote with Kerrie Mengersen and Pierre Pudlo thus examines the consequences of using an empirical likelihood in ABC contexts. Although we called the derived algorithm ABCel, it differs from genuine ABC algorithms in that it does not simulate pseudo-data. Hence the title of this post. (The title of the paper is “Approximate Bayesian computation via empirical likelihood“. It should be arXived by the time the post appears: “Your article is scheduled to be announced at Mon, 28 May 2012 00:00:00 GMT“.) We had indeed started looking at a simulated data version, but it was rather poor, and we thus opted for an importance sampling version where the parameters are simulated from an importance distribution (e.g., the prior) and then weighted by the empirical likelihood (times a regular importance factor if the importance distribution is not the prior). The above graph is an illustration in a toy example.
 Mengersen, Pudlo and Robert, 2012") The difficulty with the method is in connecting the parameters (of interest/of the assumed distribution) with moments of the (iid) data. While this operates rather straightforwardly for quantile distributions, it is less clear for dynamic models like ARCH and GARCH, where we have to reconstruct the underlying iid process. (Where ABCel clearly improves upon ABC for the GARCH(1,1) model but remains less informative than a regular MCMC analysis. Incidentally, this study led to my earlier post on the unreliable garch() function in the tseries package!) And it is even harder for population genetic models, where parameters like divergence dates, effective population sizes, mutation rates, &tc., cannot be expressed as moments of the distribution of the sample at a given locus. In particular, the datapoints are not iid. Pierre Pudlo then had the brilliant idea to resort instead to a composite likelihood, approximating the intra-locus likelihood by a product of pairwise likelihoods over all pairs of genes in the sample at a given locus. Indeed, in Kingman’s coalescent theory, the pairwise likelihoods can be expressed in closed form, hence we can derive the pairwise composite scores. The comparison with optimal ABC outcomes shows an improvement brought by ABCel in the approximation, at an overall computing cost that is negligible against ABC (i.e., it takes minutes to produce the ABCel outcome, compared with hours for ABC.)
The difficulty with the method is in connecting the parameters (of interest/of the assumed distribution) with moments of the (iid) data. While this operates rather straightforwardly for quantile distributions, it is less clear for dynamic models like ARCH and GARCH, where we have to reconstruct the underlying iid process. (Where ABCel clearly improves upon ABC for the GARCH(1,1) model but remains less informative than a regular MCMC analysis. Incidentally, this study led to my earlier post on the unreliable garch() function in the tseries package!) And it is even harder for population genetic models, where parameters like divergence dates, effective population sizes, mutation rates, &tc., cannot be expressed as moments of the distribution of the sample at a given locus. In particular, the datapoints are not iid. Pierre Pudlo then had the brilliant idea to resort instead to a composite likelihood, approximating the intra-locus likelihood by a product of pairwise likelihoods over all pairs of genes in the sample at a given locus. Indeed, in Kingman’s coalescent theory, the pairwise likelihoods can be expressed in closed form, hence we can derive the pairwise composite scores. The comparison with optimal ABC outcomes shows an improvement brought by ABCel in the approximation, at an overall computing cost that is negligible against ABC (i.e., it takes minutes to produce the ABCel outcome, compared with hours for ABC.)
We are now looking for extensions and improvements of ABCel, both at the methodological and at the genetic levels, and we would of course welcome any comment at this stage. The paper has been submitted to PNAS, as we hope it should appeal to the ABC community at large, i.e. beyond statisticians…
ABC model choice [slides]
Posted in pictures, Statistics, Travel, University life with tags ABC, asymptotics, Bayesian model choice, insufficiency, Madrid, Novermber 11, quantile distribution, sufficient statistics, summary statistics, Workshop Métodos Bayesianos 11 on November 7, 2011 by xi'an Here are the slides for my talks both at CREST this afternoon (in ½ an hour!) and in Madrid [on Friday 11/11/11=16, magical day of the year, especially since I will be speaking at 11:11 CET…] for the Workshop Métodos Bayesianos 11 (no major difference with the slides from Zürich, hey!, except for the quantile distribution example]
Here are the slides for my talks both at CREST this afternoon (in ½ an hour!) and in Madrid [on Friday 11/11/11=16, magical day of the year, especially since I will be speaking at 11:11 CET…] for the Workshop Métodos Bayesianos 11 (no major difference with the slides from Zürich, hey!, except for the quantile distribution example]
