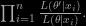Merijn Mestdagha, Stijn Verdoncka, Kristof Meersa, Tim Loossensa, and Francis Tuerlinckx from the KU Leuven, some of whom I met during a visit to its Wallon counterpart Louvain-La-Neuve, proposed and arXived a new likelihood-free approach based on saving simulations on a large scale for future users. Future users interested in the same model. The very same model. This makes the proposal quite puzzling as I have no idea as to when situations with exactly the same experimental conditions, up to the sample size, repeat over and over again. Or even just repeat once. (Some particular settings may accommodate for different sample sizes and the same prepaid database, but others as in genetics clearly do not.) I am sufficiently puzzled to suspect I have missed the message of the paper.
Merijn Mestdagha, Stijn Verdoncka, Kristof Meersa, Tim Loossensa, and Francis Tuerlinckx from the KU Leuven, some of whom I met during a visit to its Wallon counterpart Louvain-La-Neuve, proposed and arXived a new likelihood-free approach based on saving simulations on a large scale for future users. Future users interested in the same model. The very same model. This makes the proposal quite puzzling as I have no idea as to when situations with exactly the same experimental conditions, up to the sample size, repeat over and over again. Or even just repeat once. (Some particular settings may accommodate for different sample sizes and the same prepaid database, but others as in genetics clearly do not.) I am sufficiently puzzled to suspect I have missed the message of the paper.
“In various fields, statistical models of interest are analytically intractable. As a result, statistical inference is greatly hampered by computational constraint s. However, given a model, different users with different data are likely to perform similar computations. Computations done by one user are potentially useful for other users with different data sets. We propose a pooling of resources across researchers to capitalize on this. More specifically, we preemptively chart out the entire space of possible model outcomes in a prepaid database. Using advanced interpolation techniques, any individual estimation problem can now be solved on the spot. The prepaid method can easily accommodate different priors as well as constraints on the parameters. We created prepaid databases for three challenging models and demonstrate how they can be distributed through an online parameter estimation service. Our method outperforms state-of-the-art estimation techniques in both speed (with a 23,000 to 100,000-fold speed up) and accuracy, and is able to handle previously quasi inestimable models.”
I foresee potential difficulties with this proposal, like compelling all future users to rely on the same summary statistics, on the same prior distributions (the “representative amount of parameter values”), and requiring a massive storage capacity. Plus furthermore relying at its early stage on the most rudimentary form of an ABC algorithm (although not acknowledged as such), namely the rejection one. When reading the description in the paper, the proposed method indeed selects the parameters (simulated from a prior or a grid) that are producing pseudo-observations that are closest to the actual observations (or their summaries s). The subsample thus constructed is used to derive a (local) non-parametric or machine-learning predictor s=f(θ). From which a point estimator is deduced by minimising in θ a deviance d(s⁰,f(θ)).
The paper does not expand much on the theoretical justifications of the approach (including the appendix that covers a formal situation where the prepaid grid conveniently covers the observed statistics). And thus does not explain on which basis confidence intervals should offer nominal coverage for the prepaid method. Instead, the paper runs comparisons with Simon Wood’s (2010) synthetic likelihood maximisation (Ricker model with three parameters), the rejection ABC algorithm (species dispersion trait model with four parameters), while the Leaky Competing Accumulator (with four parameters as well) seemingly enjoys no alternative. Which is strange since the first step of the prepaid algorithm is an ABC step, but I am unfamiliar with this model. Unsurprisingly, in all these cases, given that the simulation has been done prior to the computing time for the prepaid method and not for either synthetic likelihood or ABC, the former enjoys a massive advantage from the start.
“The prepaid method can be used for a very large number of observations, contrary to the synthetic likelihood or ABC methods. The use of very large simulated data sets allows investigation of large-sample properties of the estimator”
To return to the general proposal and my major reservation or misunderstanding, for different experiments, the (true or pseudo-true) value of the parameter will not be the same, I presume, and hence the region of interest [or grid] will differ. While, again, the computational gain is de facto obvious [since the costly production of the reference table is not repeated], and, to repeat myself, makes the comparison with methods that do require a massive number of simulations from scratch massively in favour of the prepaid option, I do not see a convenient way of recycling these prepaid simulations for another setting, that is, when some experimental factors, sample size or collection, or even just the priors, do differ. Again, I may be missing the point, especially in a specific context like repeated psychological experiments.
 While this may have some applications in reproducibility (but maybe not, if the goal is in fact to detect cherry-picking), I see very little use in repeating the same statistical model on different datasets. Even repeating observations will require additional nuisance parameters and possibly perturb the likelihood and/or posterior to large extents.
While this may have some applications in reproducibility (but maybe not, if the goal is in fact to detect cherry-picking), I see very little use in repeating the same statistical model on different datasets. Even repeating observations will require additional nuisance parameters and possibly perturb the likelihood and/or posterior to large extents.
 A few weeks ago I gave a seminar on ABC (and its asymptotics) in the beautiful amphitheatre Marguerite de Navarre (a writer, a thinker, and a protector of writers like Rabelais and of reformist catholics, as well as th sister of the Collège founder, François I) of Collège de France, as complement of the lecture of that week by Stéphane Mallat, who is teaching this year on Learning and random sampling. In this lecture, Stéphane introduced Metropolis-Hastings as one can guess from the blackboards above! The amphitheatre was quite full since master students from several Parisian universities are following the course, along the “general public” since the first principle of the courses delivered at Collège de France is that they are open to everyone, free of charge and without preliminary registration! (As a countermeasure to the monopoly of the university of Paris, following the earlier example of the 1518 trilingual college of Louvain). Here are the slides I partly covered in the lecture.
A few weeks ago I gave a seminar on ABC (and its asymptotics) in the beautiful amphitheatre Marguerite de Navarre (a writer, a thinker, and a protector of writers like Rabelais and of reformist catholics, as well as th sister of the Collège founder, François I) of Collège de France, as complement of the lecture of that week by Stéphane Mallat, who is teaching this year on Learning and random sampling. In this lecture, Stéphane introduced Metropolis-Hastings as one can guess from the blackboards above! The amphitheatre was quite full since master students from several Parisian universities are following the course, along the “general public” since the first principle of the courses delivered at Collège de France is that they are open to everyone, free of charge and without preliminary registration! (As a countermeasure to the monopoly of the university of Paris, following the earlier example of the 1518 trilingual college of Louvain). Here are the slides I partly covered in the lecture.


 As mentioned earlier, this was my very first
As mentioned earlier, this was my very first