 This 2020 book, Measuring Abundance: Methods for the Estimation of Population Size and Species Richness was written by Graham Upton, retired professor of applied statistics, for the Data in the Wild series published by Pelagic Publishing, a publishing company based in Exeter.
This 2020 book, Measuring Abundance: Methods for the Estimation of Population Size and Species Richness was written by Graham Upton, retired professor of applied statistics, for the Data in the Wild series published by Pelagic Publishing, a publishing company based in Exeter.
“Measuring the abundance of individuals and the diversity of species are core components of most ecological research projects and conservation monitoring. This book brings together in one place, for the first time, the methods used to estimate the abundance of individuals in nature.”
Its purpose is to provide a collection of statistical methods for measuring animal abundance or lack thereof. There are four parts: a primer on statistical methods, going no further than maximum likelihood estimation and bootstrap. The term Bayesian only occurs once, in connection with the (a-Bayesian) BIC. (I first spotted a second entry, until I realised this was not a typo and the example truly was about Bawean warty pigs!) The second part is about stationary (or static) individuals, such as trees, and it mostly exposes different recognised ways of sampling, with a focus on minimising the surveyor’s effort. Examples include forestry sampling (with a chainsaw method!) and underwater sampling. There is very little statistics involved in this part apart from the rare appearance of a MLE with an asymptotic confidence interval. There is also very little about misspecified models, except for the occasional warning that the estimates may prove completely wrong. The third part is about mobile individuals, with capture-recapture methods receiving the lion’s share (!). No lion was actually involved in the studies used as examples (but there were grizzly bears from Yellowstone and Banff National Parks). Given the huge variety of capture-recapture models, very little input is found within the book as the practical aspects are delegated to R software like the RMark and mra packages. Very little is written on using covariates or spatial features in such models, mostly dedicated to printed output from R packages with AIC as the sole standard for comparing models. I did not know of distance methods (Chapter 8), which are less invasive counting methods. They however seem to rely on a particular model of missing on individuals as the distance increases. The last section is about estimating the number of species. With again a model assumption that may prove wrong. With the inclusion of diversity measures,
The contents of the book are really down to earth and intended for field data gatherers. For instance, “drive slowly and steadily at 20 mph with headlights and hazard lights on ” (p.91) or “Before starting to record, allow fish time to acclimatize to the presence of divers” (p.91). It is unclear to me how useful the book would prove to be for general statisticians, apart from revealing the huge diversity of methods actually employed in the field. To either build upon these or expose students to their reassessment. More advanced books are McCrea and Morgan (2014), Buckland et al. (2016) and the most recent Seber and Schofield (2019).
[Disclaimer about potential self-plagiarism: this post or an edited version will eventually appear in my Book Review section in CHANCE.]

![\log m(x) = \mathbb{E}^{t^0}[ \log f(X|\theta) ]](https://s0.wp.com/latex.php?latex=%5Clog+m%28x%29+%3D+%5Cmathbb%7BE%7D%5E%7Bt%5E0%7D%5B+%5Clog+f%28X%7C%5Ctheta%29+%5D&bg=000000&fg=B0B0B0&s=0&c=20201002)



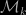 fails or may fail. The BIC approximation has the form
fails or may fail. The BIC approximation has the form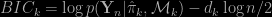
 corresponds on the number of parameters to be estimated in model
corresponds on the number of parameters to be estimated in model 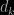 typically does not provide a good measure of complexity for model
typically does not provide a good measure of complexity for model 
 is through the effective dimension
is through the effective dimension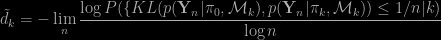
![\displaystyle \log m(\mathbf Y_n |\mathcal M_k) = \log p(\mathbf Y_n| \hat \pi_k, \mathcal M_k) - \lambda_k(\pi_0) \log n + [m_k(\pi_0) - 1] \log \log n + O_p(1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clog+m%28%5Cmathbf+Y_n+%7C%5Cmathcal+M_k%29+%3D+%5Clog+p%28%5Cmathbf+Y_n%7C+%5Chat+%5Cpi_k%2C+%5Cmathcal+M_k%29+-+%5Clambda_k%28%5Cpi_0%29+%5Clog+n+%2B+%5Bm_k%28%5Cpi_0%29+-+1%5D+%5Clog+%5Clog+n+%2B+O_p%281%29&bg=000000&fg=B0B0B0&s=0&c=20201002)
 is the true parameter. The authors propose a clever algorithm to approximate of the marginal likelihood. Given the popularity of the BIC criterion for model choice, obtaining a relevant penalized likelihood when the models are singular is an important issue and we congratulate the authors for it. Indeed a major advantage of the BIC formula is that it is an off-the-shelf crierion which is implemented in many softwares, thus can be used easily by non statisticians. In the context of singular models, a more refined approach needs to be considered and although the algorithm proposed by the authors remains quite simple, it requires that the functions
is the true parameter. The authors propose a clever algorithm to approximate of the marginal likelihood. Given the popularity of the BIC criterion for model choice, obtaining a relevant penalized likelihood when the models are singular is an important issue and we congratulate the authors for it. Indeed a major advantage of the BIC formula is that it is an off-the-shelf crierion which is implemented in many softwares, thus can be used easily by non statisticians. In the context of singular models, a more refined approach needs to be considered and although the algorithm proposed by the authors remains quite simple, it requires that the functions  and
and 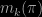 need be known in advance, which so far limitates the number of problems that can be thus processed. In this regard their equation (3.2) is both puzzling and attractive. Attractive because it invokes nonparametric principles to estimate the underlying distribution; puzzling because why should we engage into deriving an approximation like (3.1) and call for Bayesian principles when (3.1) is at best an approximation. In this case why not just use a true marginal likelihood?
need be known in advance, which so far limitates the number of problems that can be thus processed. In this regard their equation (3.2) is both puzzling and attractive. Attractive because it invokes nonparametric principles to estimate the underlying distribution; puzzling because why should we engage into deriving an approximation like (3.1) and call for Bayesian principles when (3.1) is at best an approximation. In this case why not just use a true marginal likelihood?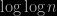 penalty is sufficient, as proved in Gassiat et al. (2013). Now whether or not this is a desirable property is entirely debatable, and one might advocate that for a given sample size, if the data fits the smallest model (almost) equally well, then this model should be chosen. But unless one is specifying what equally well means, it does not add much to the debate. This also explains the popularity of the BIC formula (in regular models), since it approximates the marginal likelihood and thus benefits from the Bayesian justification of the measure of fit of a model for a given data set, often qualified of being a Bayesian Ockham’s razor. But then why should we not compute instead the marginal likelihood? Typical answers to this question that are in favour of BIC-type formula include: (1) BIC is supposingly easier to compute and (2) BIC does not call for a specification of the prior on the parameters within each model. Given that the latter is a difficult task and that the prior can be highly influential in non-regular models, this may sound like a good argument. However, it is only apparently so, since the only justification of BIC is purely asymptotic, namely, in such a regime the difficulties linked to the choice of the prior disappear. This is even more the case for the sBIC criterion, since it is only valid if the parameter space is compact. Then the impact of the prior becomes less of an issue as non informative priors can typically be used. With all due respect, the solution proposed by the authors, namely to use the posterior mean or the posterior mode to allow for non compact parameter spaces, does not seem to make sense in this regard since they depend on the prior. The same comments apply to the author’s discussion on Prior’s matter for sBIC. Indeed variations of the sBIC could be obtained by penalizing for bigger models via the prior on the weights, for instance as in Mengersen and Rousseau (2011) or by, considering repulsive priors as in Petralia et al. (20120, but then it becomes more meaningful to (again) directly compute the marginal likelihood. Remains (as an argument in its favour) the relative computational ease of use of sBIC, when compared with the marginal likelihood. This simplification is however achieved at the expense of requiring a deeper knowledge on the behaviour of the models and it therefore looses the off-the-shelf appeal of the BIC formula and the range of applications of the method, at least so far. Although the dependence of the approximation of
penalty is sufficient, as proved in Gassiat et al. (2013). Now whether or not this is a desirable property is entirely debatable, and one might advocate that for a given sample size, if the data fits the smallest model (almost) equally well, then this model should be chosen. But unless one is specifying what equally well means, it does not add much to the debate. This also explains the popularity of the BIC formula (in regular models), since it approximates the marginal likelihood and thus benefits from the Bayesian justification of the measure of fit of a model for a given data set, often qualified of being a Bayesian Ockham’s razor. But then why should we not compute instead the marginal likelihood? Typical answers to this question that are in favour of BIC-type formula include: (1) BIC is supposingly easier to compute and (2) BIC does not call for a specification of the prior on the parameters within each model. Given that the latter is a difficult task and that the prior can be highly influential in non-regular models, this may sound like a good argument. However, it is only apparently so, since the only justification of BIC is purely asymptotic, namely, in such a regime the difficulties linked to the choice of the prior disappear. This is even more the case for the sBIC criterion, since it is only valid if the parameter space is compact. Then the impact of the prior becomes less of an issue as non informative priors can typically be used. With all due respect, the solution proposed by the authors, namely to use the posterior mean or the posterior mode to allow for non compact parameter spaces, does not seem to make sense in this regard since they depend on the prior. The same comments apply to the author’s discussion on Prior’s matter for sBIC. Indeed variations of the sBIC could be obtained by penalizing for bigger models via the prior on the weights, for instance as in Mengersen and Rousseau (2011) or by, considering repulsive priors as in Petralia et al. (20120, but then it becomes more meaningful to (again) directly compute the marginal likelihood. Remains (as an argument in its favour) the relative computational ease of use of sBIC, when compared with the marginal likelihood. This simplification is however achieved at the expense of requiring a deeper knowledge on the behaviour of the models and it therefore looses the off-the-shelf appeal of the BIC formula and the range of applications of the method, at least so far. Although the dependence of the approximation of  on
on  , $latex {j \leq k} is strange, this does not seem crucial, since marginal likelihoods in themselves bring little information and they are only meaningful when compared to other marginal likelihoods. It becomes much more of an issue in the context of a large number of models.
, $latex {j \leq k} is strange, this does not seem crucial, since marginal likelihoods in themselves bring little information and they are only meaningful when compared to other marginal likelihoods. It becomes much more of an issue in the context of a large number of models.
