
Another X validated question of some interest: how to infer about the parameters of a model when only given a fraction 1-α of the order statistics. For instance, the (1-α)n largest observations. On a primary level, the answer is somewhat obvious since the joint density of these observations is available in closed form. At another level, it brings out the fact that the distribution of the unobserved part of the sample given the observed one only depends on the smallest observed order statistic ς (which is thus sufficient in that sense) and ends up being the original distribution truncated at ς, which allows for a closed form EM implementation. Which is also interesting given that the moments of a Normal order statistic are not available in closed form. This reminded me of the insufficient Gibbs paper we wrote with Antoine and Robin a few months ago, except for the available likelihood. And provided fodder for the final exam of my introductory mathematical statistics course at Paris Dauphine.

 This early morning in NYC, I spotted this
This early morning in NYC, I spotted this 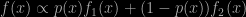

![E(\theta'|\theta)=\mathbb E_{\theta}[\log\,f_{X,Z}(x^\text{obs},Z|\theta')|X=x^\text{obs}]](https://s0.wp.com/latex.php?latex=E%28%5Ctheta%27%7C%5Ctheta%29%3D%5Cmathbb+E_%7B%5Ctheta%7D%5B%5Clog%5C%2Cf_%7BX%2CZ%7D%28x%5E%5Ctext%7Bobs%7D%2CZ%7C%5Ctheta%27%29%7CX%3Dx%5E%5Ctext%7Bobs%7D%5D&bg=000000&fg=B0B0B0&s=0&c=20201002)
![\log\,f_X(x^\text{obs};\theta')+\mathbb E_{\theta}[\log\,f_{Z|X}(Z|x^\text{obs},\theta')|X=x^\text{obs}]](https://s0.wp.com/latex.php?latex=%5Clog%5C%2Cf_X%28x%5E%5Ctext%7Bobs%7D%3B%5Ctheta%27%29%2B%5Cmathbb+E_%7B%5Ctheta%7D%5B%5Clog%5C%2Cf_%7BZ%7CX%7D%28Z%7Cx%5E%5Ctext%7Bobs%7D%2C%5Ctheta%27%29%7CX%3Dx%5E%5Ctext%7Bobs%7D%5D&bg=000000&fg=B0B0B0&s=0&c=20201002)
![\log\,f_X(x^\text{obs};\theta')=\log\,\mathbb E_{\theta}\left[\frac{f_{X,Z}(x^\text{obs},Z;\theta')}{f_{Z|X}(Z|x^\text{obs},\theta)}\big|X=x^\text{obs}\right]](https://s0.wp.com/latex.php?latex=%5Clog%5C%2Cf_X%28x%5E%5Ctext%7Bobs%7D%3B%5Ctheta%27%29%3D%5Clog%5C%2C%5Cmathbb+E_%7B%5Ctheta%7D%5Cleft%5B%5Cfrac%7Bf_%7BX%2CZ%7D%28x%5E%5Ctext%7Bobs%7D%2CZ%3B%5Ctheta%27%29%7D%7Bf_%7BZ%7CX%7D%28Z%7Cx%5E%5Ctext%7Bobs%7D%2C%5Ctheta%29%7D%5Cbig%7CX%3Dx%5E%5Ctext%7Bobs%7D%5Cright%5D&bg=000000&fg=B0B0B0&s=0&c=20201002)

