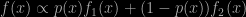Over a sunny if quarantined Sunday, I started reading the PhD dissertation of Rob Cornish, Oxford University, as I am the external member of his viva committee. Ending up in a highly pleasant afternoon discussing this thesis over a (remote) viva yesterday. (If bemoaning a lost opportunity to visit Oxford!) The introduction to the viva was most helpful and set the results within the different time and geographical zones of the Ph.D since Rob had to switch from one group of advisors in Engineering to another group in Statistics. Plus an encompassing prospective discussion, expressing pessimism at exact MCMC for complex models and looking forward further advances in probabilistic programming.
Over a sunny if quarantined Sunday, I started reading the PhD dissertation of Rob Cornish, Oxford University, as I am the external member of his viva committee. Ending up in a highly pleasant afternoon discussing this thesis over a (remote) viva yesterday. (If bemoaning a lost opportunity to visit Oxford!) The introduction to the viva was most helpful and set the results within the different time and geographical zones of the Ph.D since Rob had to switch from one group of advisors in Engineering to another group in Statistics. Plus an encompassing prospective discussion, expressing pessimism at exact MCMC for complex models and looking forward further advances in probabilistic programming.
Made of three papers, the thesis includes this ICML 2019 [remember the era when there were conferences?!] paper on scalable Metropolis-Hastings, by Rob Cornish, Paul Vanetti, Alexandre Bouchard-Côté, Georges Deligiannidis, and Arnaud Doucet, which I commented last year. Which achieves a remarkable and paradoxical O(1/√n) cost per iteration, provided (global) lower bounds are found on the (local) Metropolis-Hastings acceptance probabilities since they allow for Poisson thinning à la Devroye (1986) and second order Taylor expansions constructed for all components of the target, with the third order derivatives providing bounds. However, the variability of the acceptance probability gets higher, which induces a longer but still manageable if the concentration of the posterior is in tune with the Bernstein von Mises asymptotics. I had not paid enough attention in my first read at the strong theoretical justification for the method, relying on the convergence of MAP estimates in well- and (some) mis-specified settings. Now, I would have liked to see the paper dealing with a more complex problem that logistic regression.
The second paper in the thesis is an ICML 2018 proceeding by Tom Rainforth, Robert Cornish, Hongseok Yang, Andrew Warrington, and Frank Wood, which considers Monte Carlo problems involving several nested expectations in a non-linear manner, meaning that (a) several levels of Monte Carlo approximations are required, with associated asymptotics, and (b) the resulting overall estimator is biased. This includes common doubly intractable posteriors, obviously, as well as (Bayesian) design and control problems. [And it has nothing to do with nested sampling.] The resolution chosen by the authors is strictly plug-in, in that they replace each level in the nesting with a Monte Carlo substitute and do not attempt to reduce the bias. Which means a wide range of solutions (other than the plug-in one) could have been investigated, including bootstrap maybe. For instance, Bayesian design is presented as an application of the approach, but since it relies on the log-evidence, there exist several versions for estimating (unbiasedly) this log-evidence. Similarly, the Forsythe-von Neumann technique applies to arbitrary transforms of a primary integral. The central discussion dwells on the optimal choice of the volume of simulations at each level, optimal in terms of asymptotic MSE. Or rather asymptotic bound on the MSE. The interesting result being that the outer expectation requires the square of the number of simulations for the other expectations. Which all need converge to infinity. A trick in finding an estimator for a polynomial transform reminded me of the SAME algorithm in that it duplicated the simulations as many times as the highest power of the polynomial. (The ‘Og briefly reported on this paper… four years ago.)
 The third and last part of the thesis is a proposal [to appear in ICML 20] on relaxing bijectivity constraints in normalising flows with continuously index flows. (Or CIF. As Rob made a joke about this cleaning brand, let me add (?) to that joke by mentioning that looking at CIF and bijections is less dangerous in a Trump cum COVID era at CIF and injections!) With Anthony Caterini, George Deligiannidis and Arnaud Doucet as co-authors. I am much less familiar with this area and hence a wee bit puzzled at the purpose of removing what I understand to be an appealing side of normalising flows, namely to produce a manageable representation of density functions as a combination of bijective and differentiable functions of a baseline random vector, like a standard Normal vector. The argument made in the paper is that imposing this representation of the density imposes a constraint on the topology of its support since said support is homeomorphic to the support of the baseline random vector. While the supporting theoretical argument is a mathematical theorem that shows the Lipschitz bound on the transform should be infinity in the case the supports are topologically different, these arguments may be overly theoretical when faced with the practical implications of the replacement strategy. I somewhat miss its overall strength given that the whole point seems to be in approximating a density function, based on a finite sample.
The third and last part of the thesis is a proposal [to appear in ICML 20] on relaxing bijectivity constraints in normalising flows with continuously index flows. (Or CIF. As Rob made a joke about this cleaning brand, let me add (?) to that joke by mentioning that looking at CIF and bijections is less dangerous in a Trump cum COVID era at CIF and injections!) With Anthony Caterini, George Deligiannidis and Arnaud Doucet as co-authors. I am much less familiar with this area and hence a wee bit puzzled at the purpose of removing what I understand to be an appealing side of normalising flows, namely to produce a manageable representation of density functions as a combination of bijective and differentiable functions of a baseline random vector, like a standard Normal vector. The argument made in the paper is that imposing this representation of the density imposes a constraint on the topology of its support since said support is homeomorphic to the support of the baseline random vector. While the supporting theoretical argument is a mathematical theorem that shows the Lipschitz bound on the transform should be infinity in the case the supports are topologically different, these arguments may be overly theoretical when faced with the practical implications of the replacement strategy. I somewhat miss its overall strength given that the whole point seems to be in approximating a density function, based on a finite sample.
 This early morning in NYC, I spotted this new arXival by Marco Bee (whom I know from the time he was writing his PhD with my late friend Bernhard Flury) and found he has been working for a while on ABC related problems. The mixture model he considers therein is a form of mixture of experts, where the weights of the mixture components are not constant but functions on (0,1) of the entry as well. This model was introduced by Frigessi, Haug and Rue in 2002 and is often used as a benchmark for ABC methods, since it is missing its normalising constant as in e.g.
This early morning in NYC, I spotted this new arXival by Marco Bee (whom I know from the time he was writing his PhD with my late friend Bernhard Flury) and found he has been working for a while on ABC related problems. The mixture model he considers therein is a form of mixture of experts, where the weights of the mixture components are not constant but functions on (0,1) of the entry as well. This model was introduced by Frigessi, Haug and Rue in 2002 and is often used as a benchmark for ABC methods, since it is missing its normalising constant as in e.g.