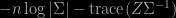This early morning in NYC, I spotted this new arXival by Marco Bee (whom I know from the time he was writing his PhD with my late friend Bernhard Flury) and found he has been working for a while on ABC related problems. The mixture model he considers therein is a form of mixture of experts, where the weights of the mixture components are not constant but functions on (0,1) of the entry as well. This model was introduced by Frigessi, Haug and Rue in 2002 and is often used as a benchmark for ABC methods, since it is missing its normalising constant as in e.g.
This early morning in NYC, I spotted this new arXival by Marco Bee (whom I know from the time he was writing his PhD with my late friend Bernhard Flury) and found he has been working for a while on ABC related problems. The mixture model he considers therein is a form of mixture of experts, where the weights of the mixture components are not constant but functions on (0,1) of the entry as well. This model was introduced by Frigessi, Haug and Rue in 2002 and is often used as a benchmark for ABC methods, since it is missing its normalising constant as in e.g.
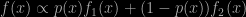
even with all entries being standard pdfs and cdfs. Rather than using a (costly) numerical approximation of the “constant” (as a function of all unknown parameters involved), Marco follows the approximate maximum likelihood approach of my Warwick colleagues, Javier Rubio [now at UCL] and Adam Johansen. It is based on the [SAME] remark that under a uniform prior and using an approximation to the actual likelihood the MAP estimator is also the MLE for that approximation. The approximation is ABC-esque in that a pseudo-sample is generated from the true model (attached to a simulation of the parameter) and the pair is accepted if the pseudo-sample stands close enough to the observed sample. The paper proposes to use the Cramér-von Mises distance, which only involves ranks. Given this “posterior” sample, an approximation of the posterior density is constructed and then numerically optimised. From a frequentist view point, a direct estimate of the mode would be preferable. From my Bayesian perspective, this sounds like a step backwards, given that once a posterior sample is available, reconnecting with an approximate MLE does not sound highly compelling.