
Archive for NYC
fat tire [jatp]
Posted in Statistics with tags amber beer, Belgian beer, Colorado, delivery vans, Fat Tire, jatp, microbrewery, New Belgium, New York city, NYC, street view on January 20, 2023 by xi'an
leaves & masks [cover]
Posted in Books, Kids, pictures, Travel with tags cover, dead leaves, face mask, Fall, Fall sweep, New York, NYC, The New Yorker on December 13, 2022 by xi'an
New York City trip
Posted in pictures, Running, Travel with tags Donald Trump, electric bike, Flatiron building, Hudson river, Manhattan, matcha tea, NYC, Queensboro Bridge, Roosevelt Island, scooter, UN building on December 8, 2022 by xi'an
 While the Sampling, Transport, Diffusion workshop at the Flatiron Institute kept me happily busy, and while I did not stay any longer, spending a few days in New York City was a treat and I took advantage of my early hours to go running along the river sides, first south of the Flatiron building, then north to the Queensboro Bridge and over it, and last north along the Hudson River. The East River side is much less convenient for running as the path is repeatedly blocked by construction / storage sites and Xing the Queensboro Bridge gave a great view of Manhattan, albeit at the risk of being hit by a bike / scooter / moppet, as the path was shared with [an endless flow of] speeding electric bicycles. As I had never been to this part of the city, I was unaware of the cable car / gondola to Roosevelt Island (surprisingly called tram), which I would have taken given an extra day. Came by uponchance over a Trump Tower, which I ignored was so inappropriately close to the UN Headquarters! Running on the uninterrupted Hudson River trail was much nicer (and busier) despite the freezing wind that day.
While the Sampling, Transport, Diffusion workshop at the Flatiron Institute kept me happily busy, and while I did not stay any longer, spending a few days in New York City was a treat and I took advantage of my early hours to go running along the river sides, first south of the Flatiron building, then north to the Queensboro Bridge and over it, and last north along the Hudson River. The East River side is much less convenient for running as the path is repeatedly blocked by construction / storage sites and Xing the Queensboro Bridge gave a great view of Manhattan, albeit at the risk of being hit by a bike / scooter / moppet, as the path was shared with [an endless flow of] speeding electric bicycles. As I had never been to this part of the city, I was unaware of the cable car / gondola to Roosevelt Island (surprisingly called tram), which I would have taken given an extra day. Came by uponchance over a Trump Tower, which I ignored was so inappropriately close to the UN Headquarters! Running on the uninterrupted Hudson River trail was much nicer (and busier) despite the freezing wind that day.
 For once (!) I stayed in an hotel, reserved by the Flatiron, and for the three nights I was there it was most tolerable, except for the usual background noise found in hotels, both from heating fans and patrons discussing in the corridors after hours. But the staff was helpful to the point of purchasing a kettle for my early morning tea. As the workshop provided an enormous amount of food at all times (and there was a true matcha tea provider around the corner!), it did not matter in the least.
For once (!) I stayed in an hotel, reserved by the Flatiron, and for the three nights I was there it was most tolerable, except for the usual background noise found in hotels, both from heating fans and patrons discussing in the corridors after hours. But the staff was helpful to the point of purchasing a kettle for my early morning tea. As the workshop provided an enormous amount of food at all times (and there was a true matcha tea provider around the corner!), it did not matter in the least.
semi de Boulogne [1:29:33, 1243/8134, M5M 6/206, 8⁰+rain]
Posted in pictures, Running with tags Argentan half-marathon, bois de Boulogne, half-marathon, NYC, race, Seine, semi-marathon, training on December 1, 2022 by xi'an First time back to the Boulogne half-marathon since 2008! With clearly a much degraded time, albeit better than the previous race in Argentan. The route has changed, with a longer part in the Bois de Boulogne, sharing the road with the hordes of Sunday cyclists that pile up loops at high speed. But still a very fast one (with a record at 1:00:11 in 2013). The number has alas considerably increased since my last visit, with 9800 registrations, which makes running in the first kilometers a challenge with hidden sidewalks, parked cars and moppets, &tc. And a permanent difficulty in passing other runners, especially on a rainy day. (The only good side was being protected from headwinds.)
First time back to the Boulogne half-marathon since 2008! With clearly a much degraded time, albeit better than the previous race in Argentan. The route has changed, with a longer part in the Bois de Boulogne, sharing the road with the hordes of Sunday cyclists that pile up loops at high speed. But still a very fast one (with a record at 1:00:11 in 2013). The number has alas considerably increased since my last visit, with 9800 registrations, which makes running in the first kilometers a challenge with hidden sidewalks, parked cars and moppets, &tc. And a permanent difficulty in passing other runners, especially on a rainy day. (The only good side was being protected from headwinds.) Once on the road by the Seine River, I managed to pass a large group conglomerated around a (1:30) pace setter and moved at my own speed, till Km16 when I started to tire and realise I was alas missing some volume of training (as running in NYC was only a slow-paced jogging). Hence wasting about a minute on the final four kilometers… (Jogging back after the race to my car, parked 3km away, proved rather painful!) As the 1:30 time was my upper limit, I am still reasonably fine with the result (and the 4’14” per km) and hope I can train harder for the next race.
Once on the road by the Seine River, I managed to pass a large group conglomerated around a (1:30) pace setter and moved at my own speed, till Km16 when I started to tire and realise I was alas missing some volume of training (as running in NYC was only a slow-paced jogging). Hence wasting about a minute on the final four kilometers… (Jogging back after the race to my car, parked 3km away, proved rather painful!) As the 1:30 time was my upper limit, I am still reasonably fine with the result (and the 4’14” per km) and hope I can train harder for the next race.
dynamic mixtures and frequentist ABC
Posted in Statistics with tags ABC, approximate maximum likelihood, Arnoldo Frigessi, Bernhard Flury, Cramèr-von Mises distance, dynamic mixture, EM, EM algorithm, indirect inference, map, MLE, mode, NYC, rank statistics, SAME algorithm, summary statistics on November 30, 2022 by xi'an This early morning in NYC, I spotted this new arXival by Marco Bee (whom I know from the time he was writing his PhD with my late friend Bernhard Flury) and found he has been working for a while on ABC related problems. The mixture model he considers therein is a form of mixture of experts, where the weights of the mixture components are not constant but functions on (0,1) of the entry as well. This model was introduced by Frigessi, Haug and Rue in 2002 and is often used as a benchmark for ABC methods, since it is missing its normalising constant as in e.g.
This early morning in NYC, I spotted this new arXival by Marco Bee (whom I know from the time he was writing his PhD with my late friend Bernhard Flury) and found he has been working for a while on ABC related problems. The mixture model he considers therein is a form of mixture of experts, where the weights of the mixture components are not constant but functions on (0,1) of the entry as well. This model was introduced by Frigessi, Haug and Rue in 2002 and is often used as a benchmark for ABC methods, since it is missing its normalising constant as in e.g.
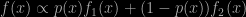
even with all entries being standard pdfs and cdfs. Rather than using a (costly) numerical approximation of the “constant” (as a function of all unknown parameters involved), Marco follows the approximate maximum likelihood approach of my Warwick colleagues, Javier Rubio [now at UCL] and Adam Johansen. It is based on the [SAME] remark that under a uniform prior and using an approximation to the actual likelihood the MAP estimator is also the MLE for that approximation. The approximation is ABC-esque in that a pseudo-sample is generated from the true model (attached to a simulation of the parameter) and the pair is accepted if the pseudo-sample stands close enough to the observed sample. The paper proposes to use the Cramér-von Mises distance, which only involves ranks. Given this “posterior” sample, an approximation of the posterior density is constructed and then numerically optimised. From a frequentist view point, a direct estimate of the mode would be preferable. From my Bayesian perspective, this sounds like a step backwards, given that once a posterior sample is available, reconnecting with an approximate MLE does not sound highly compelling.
