 Alexander Buchholz (who did his PhD at CREST with Nicolas Chopin), Daniel Ahfock, and my friend Sylvia Richardson published a great paper on the distributed computation of Bayesian evidence in Bayesian Analysis. The setting is one of distributed data from several sources with no communication between them, which relates to consensus Monte Carlo even though model choice has not been particularly studied from that perspective. The authors operate under the assumption of conditionally conjugate models, i.e., the existence of a data augmentation scheme into an exponential family so that conjugate priors can be used. For a division of the data into S blocks, the fundamental identity in the paper is
Alexander Buchholz (who did his PhD at CREST with Nicolas Chopin), Daniel Ahfock, and my friend Sylvia Richardson published a great paper on the distributed computation of Bayesian evidence in Bayesian Analysis. The setting is one of distributed data from several sources with no communication between them, which relates to consensus Monte Carlo even though model choice has not been particularly studied from that perspective. The authors operate under the assumption of conditionally conjugate models, i.e., the existence of a data augmentation scheme into an exponential family so that conjugate priors can be used. For a division of the data into S blocks, the fundamental identity in the paper is

where α is the normalising constant of the sub-prior exp{log[p(θ)]/S} and the other terms are associated with this prior. Under the conditionally conjugate assumption, the integral can be approximated based on the latent variables. Most interestingly, the associated variance is directly connected with the variance of
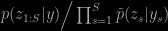
under the joint:
“The variance of the ratio measures the quality of the product of the conditional sub-posterior as an importance sample proposal distribution.”
Assuming this variance is finite (which is likely). An approximate alternative is proposed, namely to replace the exact sub-posterior with a Normal distribution, as in consensus Monte Carlo, which should obviously require some consideration as to which parameterisation of the model produces the “most normal” (or the least abnormal!) posterior. And ensures a finite variance in the importance sampling approximation (as ensured by the strong bounds in Proposition 5). A problem shared by the bridgesampling package.
“…if the error that comes from MCMC sampling is relatively small and that the shard sizes are large enough so that the quality of the subposterior normal approximation is reasonable, our suggested approach will result in good approximations of the full data set marginal likelihood.”
The resulting approximation can also be handy in conjunction with reversible jump MCMC, in the sense that RJMCMC algorithms can be run in parallel on different chunks or shards of the entire dataset. Although the computing gain may be reduced by the need for separate approximations.



 When Andrew was in Paris, we discussed at length about using EP for handling big datasets in a different way than running parallel MCMC. A related preprint came out on
When Andrew was in Paris, we discussed at length about using EP for handling big datasets in a different way than running parallel MCMC. A related preprint came out on 