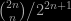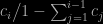Bayes Rules! is a new introductory textbook on Applied Bayesian Model(l)ing, written by Alicia Johnson (Macalester College), Miles Ott (Johnson & Johnson), and Mine Dogucu (University of California Irvine). Textbook sent to me by CRC Press for review. It is available (free) online as a website and has a github site, as well as a bayesrule R package. (Which reminds me that both our own book R packages, bayess and mcsm, have gone obsolete on CRAN! And that I should find time to figure out the issue for an upgrading…)
Bayes Rules! is a new introductory textbook on Applied Bayesian Model(l)ing, written by Alicia Johnson (Macalester College), Miles Ott (Johnson & Johnson), and Mine Dogucu (University of California Irvine). Textbook sent to me by CRC Press for review. It is available (free) online as a website and has a github site, as well as a bayesrule R package. (Which reminds me that both our own book R packages, bayess and mcsm, have gone obsolete on CRAN! And that I should find time to figure out the issue for an upgrading…)
As far as I can tell [from abroad and from only teaching students with a math background], Bayes Rules! seems to be catering to early (US) undergraduate students with very little exposure to mathematical statistics or probability, as it introduces basic probability notions like pmf, joint distribution, and Bayes’ theorem (as well as Greek letters!) and shies away from integration or algebra (a covariance matrix occurs on page 437 with a lot . For instance, the Normal-Normal conjugacy derivation is considered a “mouthful” (page 113). The exposition is somewhat stretched along the 500⁺ pages as a result, imho, which is presumably a feature shared with most textbooks at this level, and, accordingly, the exercises and quizzes are more about intuition and reproducing the contents of the chapter than technical. In fact, I did not spot there a mention of sufficiency, consistency, posterior concentration (almost made on page 113), improper priors, ergodicity, irreducibility, &tc., while other notions are not precisely defined, like ESS, weakly informative (page 234) or vague priors (page 77), prior information—which makes the negative answer to the quiz “All priors are informative” (page 90) rather confusing—, R-hat, density plot, scaled likelihood, and more.
As an alternative to “technical derivations” Bayes Rules! centres on intuition and simulation (yay!) via its bayesrule R package. Itself relying on rstan. Learning from example (as R code is always provided), the book proceeds through conjugate priors, MCMC (Metropolis-Hasting) methods, regression models, and hierarchical regression models. Quite impressive given the limited prerequisites set by the authors. (I appreciated the representations of the prior-likelihood-posterior, especially in the sequential case.)
Regarding the “hot tip” (page 108) that the posterior mean always stands between the prior mean and the data mean, this should be made conditional on a conjugate setting and a mean parameterisation. Defining MCMC as a method that produces a sequence of realisations that are not from the target makes a point, except of course that there are settings where the realisations are from the target, for instance after a renewal event. Tuning MCMC should remain a partial mystery to readers after reading Chapter 7 as the Goldilocks principle is quite vague. Similarly, the derivation of the hyperparameters in a novel setting (not covered by the book) should prove a challenge, even though the readers are encouraged to “go forth and do some Bayes things” (page 509).

While Bayes factors are supported for some hypothesis testing (with no point null), model comparison follows more exploratory methods like X validation and expected log-predictive comparison.
The examples and exercises are diverse (if mostly US centric), modern (including cultural references that completely escape me), and often reflect on the authors’ societal concerns. In particular, their concern about a fair use of the inferred models is preminent, even though a quantitative assessment of the degree of fairness would require a much more advanced perspective than the book allows… (In that respect, Exercise 18.2 and the following ones are about book banning (in the US). Given the progressive tone of the book, and the recent ban of math textbooks in the US, I wonder if some conservative boards would consider banning it!) Concerning the Himalaya submitting running example (Chapters 18 & 19), where the probability to summit is conditional on the age of the climber and the use of additional oxygen, I am somewhat surprised that the altitude of the targeted peak is not included as a covariate. For instance, Ama Dablam (6848 m) is compared with Annapurna I (8091 m), which has the highest fatality-to-summit ratio (38%) of all. This should matter more than age: the Aosta guide Abele Blanc climbed Annapurna without oxygen at age 57! More to the point, the (practical) detailed examples do not bring unexpected conclusions, as for instance the fact that runners [thrice alas!] tend to slow down with age.
A geographical comment: Uluru (page 267) is not a city!, but an impressive sandstone monolith in the heart of Australia, a 5 hours drive away from Alice Springs. And historical mentions: Alan Turing (page 10) and the team at Bletchley Park indeed used Bayes factors (and sequential analysis) in cracking the Enigma, but this remained classified information for quite a while. Arianna Rosenbluth (page 10, but missing on page 165) was indeed a major contributor to Metropolis et al. (1953, not cited), but would not qualify as a Bayesian statistician as the goal of their algorithm was a characterisation of the Boltzman (or Gibbs) distribution, not statistical inference. And David Blackwell’s (page 10) Basic Statistics is possibly the earliest instance of an introductory Bayesian and decision-theory textbook, but it never mentions Bayes or Bayesianism.
[Disclaimer about potential self-plagiarism: this post or an edited version will eventually appear in my Book Review section in CHANCE.]