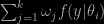Thanks to an X validated question, I re-read Radford Neal’s 2003 Slice sampling paper. Which is an Annals of Statistics discussion paper, and rightly so. While I was involved in the editorial processing of this massive paper (!), I had only vague memories left about it. Slice sampling has this appealing feature of being the equivalent of random walk Metropolis-Hastings for Gibbs sampling, without the drawback of setting a scale for the moves.
Thanks to an X validated question, I re-read Radford Neal’s 2003 Slice sampling paper. Which is an Annals of Statistics discussion paper, and rightly so. While I was involved in the editorial processing of this massive paper (!), I had only vague memories left about it. Slice sampling has this appealing feature of being the equivalent of random walk Metropolis-Hastings for Gibbs sampling, without the drawback of setting a scale for the moves.
“These slice sampling methods can adaptively change the scale of changes made, which makes them easier to tune than Metropolis methods and also avoids problems that arise when the appropriate scale of changes varies over the distribution (…) Slice sampling methods that improve sampling by suppressing random walks can also be constructed.” (p.706)
One major theme in the paper is fighting random walk behaviour, of which Radford is a strong proponent. Even at the present time, I am a bit surprised by this feature as component-wise slice sampling is exhibiting clear features of a random walk, exploring the subgraph of the target by random vertical and horizontal moves. Hence facing the potential drawback of backtracking to previously visited places.
“A Markov chain consisting solely of overrelaxed updates might not be ergodic.” (p.729)
Overrelaxation is presented as a mean to avoid the random walk behaviour by removing rejections. The proposal is actually deterministic projecting the current value to the “other side” of the approximate slice. If it stays within the slice it is accepted. This “reflection principle” [in that it takes the symmetric wrt the centre of the slice] is also connected with antithetic sampling in that it induces rather negative correlation between the successive simulations. The last methodological section covers reflective slice sampling, which appears as a slice version of Hamiltonian Monte Carlo (HMC). Given the difficulty in implementing exact HMC (reflected in the later literature), it is no wonder that Radford proposes an approximation scheme that is valid if somewhat involved.
“We can show invariance of this distribution by showing (…) detailed balance, which for a uniform distribution reduces to showing that the probability density for x¹ to be selected as the next state, given that the current state is x0, is the same as the probability density for x⁰ to be the next state, given that x¹ is the current state, for any states x⁰ and x¹ within [the slice] S.” (p.718)
In direct connection with the X validated question there is a whole section of the paper on implementing single-variable slice sampling that I had completely forgotten, with a collection of practical implementations when the slice
S={x; u < f(x) }
cannot be computed in an exact manner. Like the “stepping out” procedure. The resulting set (interval) where the uniform simulation in x takes place may well miss some connected component(s) of the slice. This quote may sound like a strange argument in that the move may well leave a part of the slice off and still satisfy this condition. Not really since it states that it must hold for any pair of states within S… The very positive side of this section is to allow for slice sampling in cases where the inversion of u < f(x) is intractable. Hence with a strong practical implication. The multivariate extension of the approximation procedure is more (potentially) fraught with danger in that it may fell victim to a curse of dimension, in that the box for the uniform simulation of x may be much too large when compared with the true slice (or slice of the slice). I had more of a memory of the “trail of crumbs” idea, mostly because of the name I am afraid!, which links with delayed rejection, as indicated in the paper, but seems awfully delicate to calibrate.