
Archive for Lenzerheide
Le Sassine
Posted in Mountains, pictures, Travel, Wines with tags Italian wines, Le Sassine, Lenzerheide, MCMskv, Ripasso, Switzerland, Valpolicella on May 20, 2016 by xi'an
Villa Arvedi
Posted in Mountains, pictures, Travel, Wines with tags airbnb, Amarone della Valpolicella, Italian wine, Lenzerheide, MCMskv, Switzerland, Valpantena on March 20, 2016 by xi'an
next BayesComp conference planned for Jan 2018, any volunteer?
Posted in Kids, Mountains, Statistics, Travel, University life with tags Adapski, BayesComp, Bayesian computing, Bayesian Computing Section, Bayesian conference, BC2018, Bormio, Chamonix, ISBA, Italy, Lenzerheide, MCMC, MCMSki, Monte Carlo Statistical Methods, Park City, satellite workshop, Switzerland, Utah on February 25, 2016 by xi'an [A call from the BayesComp section of ISBA for the next Bayesian computation meeting! As suggested in an earlier post, the label MCMski is discontinued to allow for any location amenable to organise a 200 plus meeting in good and hopefully reasonably priced conditions.]
[A call from the BayesComp section of ISBA for the next Bayesian computation meeting! As suggested in an earlier post, the label MCMski is discontinued to allow for any location amenable to organise a 200 plus meeting in good and hopefully reasonably priced conditions.]
The Bayesian Computation Section of ISBA is soliciting proposals to host its flagship meeting: BayesComp 2018
The expectation is that the meeting will be held in January 2018, but the committee will consider proposals for other times through January 2019. This meeting is a continuation of the popular MCMSki on recent advances in the theory and application of Bayesian computational methods such as MCMC. The tradition was to hold MCMski meetings in ski resorts, but, as the name change suggests, we encourage applications from any venue that could support BC2018.
A three-day meeting is planned, perhaps with an additional day or two of satellite meetings and/or short courses. One page proposals should address feasibility of hosting the meeting including
1. Proposed dates.
2. Transportation for international participants (both the proximity of international airports and transportation to/from the venue).
3. The conference facilities.
4. The availability and cost of hotels, including low cost options.
5. The proposed local organizing committee and their collective experience organizing international meetings.
6. Expected or promised contributions from the host organization, host country, or industrial partners towards the cost of running the meetings.
Proposals should be submitted to Nicolas Chopin (Program Chair) no later than May 31, 2016. The Board of Bayesian Computing Section will evaluate the proposals, choose a venue, and appoint the Program Committee for BayesComp 2018.
MCMskv #5 [future with a view]
Posted in Kids, Mountains, R, Statistics, Travel, University life with tags airbnb, approximate likelihood, asynchronous algorithms, BayesComp, BAYSM, big data, computational complexity, exact Monte Carlo, Lenzerheide, likelihood-free methods, MCMC convergence, MCMskv, Metropolis-Hastings algorithm, noisy Metropolis-Hastings algorithm, quasi-Monte Carlo methods, snow, Switzerland on January 12, 2016 by xi'an As I am flying back to Paris (with an afternoon committee meeting in München in-between), I am reminiscing on the superlative scientific quality of this MCMski meeting, on the novel directions in computational Bayesian statistics exhibited therein, and on the potential settings for the next meeting. If any.
As I am flying back to Paris (with an afternoon committee meeting in München in-between), I am reminiscing on the superlative scientific quality of this MCMski meeting, on the novel directions in computational Bayesian statistics exhibited therein, and on the potential settings for the next meeting. If any.
First, as hopefully obvious from my previous entries, I found the scientific program very exciting, with almost uniformly terrific talks, and a coverage of the field of computational Bayesian statistics that is perfectly tuned to my own interest. In that sense, MCMski is my “top one” conference! Even without considering the idyllic location. While some of the talks were about papers I had already read (and commented here), others brought new vistas and ideas. If one theme is to emerge from this meeting it has to be the one of approximate and noisy algorithms, with a wide variety of solutions and approaches to overcome complexity issues. If anything, I wish the solutions would also incorporate the Boxian fact that the statistical models themselves are approximate. Overall, a fantastic program (says one member of the scientific committee).
Second, as with previous MCMski meetings, I again enjoyed the unique ambience of the meeting, which always feels more relaxed and friendly than other conferences of a similar size, maybe because of the après-ski atmosphere or of the special coziness provided by luxurious mountain hotels. This year hotel was particularly pleasant, with non-guests like myself able to partake of some of their facilities. A big thank you to Anto for arranging so meticulously all the details of such a large meeting!!! I am even more grateful when realising this is the third time Anto takes over the heavy load of organising MCMski. Grazie mille!
Since this is a [and even the!] BayesComp conference, the current section program chair and board must decide on the structure and schedule of the next meeting. A few suggestions if I may: I would scrap entirely the name MCMski from the next conference as (a) it may sound like academic tourism for unaware bystanders (who only need to check the program of any of the MCMski conferences to stand reassured!) and (b) its topic go way beyond MCMC. Given the large attendance and equally large proportion of young researchers, I would also advise against hosting the conference in a ski resort for both cost and accessibility reasons [as we had already discussed after MCMskiv], in favour of a large enough town to offer a reasonable range of accommodations and of travel options. Like Chamonix, Innsbruck, Reykjavik, or any place with a major airport about one hour away… If nothing is available with skiing possibilities, so be it! While the outdoor inclinations of the early organisers induced us to pick locations where skiing over lunch break was a perk, any accessible location that allows for a concentration of researchers in a small area and for the ensuing day-long exchange is fine! Among the novelties in the program, the tutorials and the Breaking news! sessions were quite successful (says one member of the scientific committee). And should be continued in one format or another. Maybe a more programming thread could be added as well… And as we had mentioned earlier, to see a stronger involvement of the Young Bayesian section in the program would be great! (Even though the current meeting already had many young researcher talks.)
mixtures are slices of an orange
Posted in Kids, R, Statistics with tags CFE 2015, Gaussian mixture, hyperparameter, improper priors, invariance, Lenzerheide, location-scale parameterisation, London, MCMskv, Metropolis-Hastings algorithm, mixtures of distributions, non-informative priors, poster, R, reference priors, Switzerland, Ultimixt on January 11, 2016 by xi'an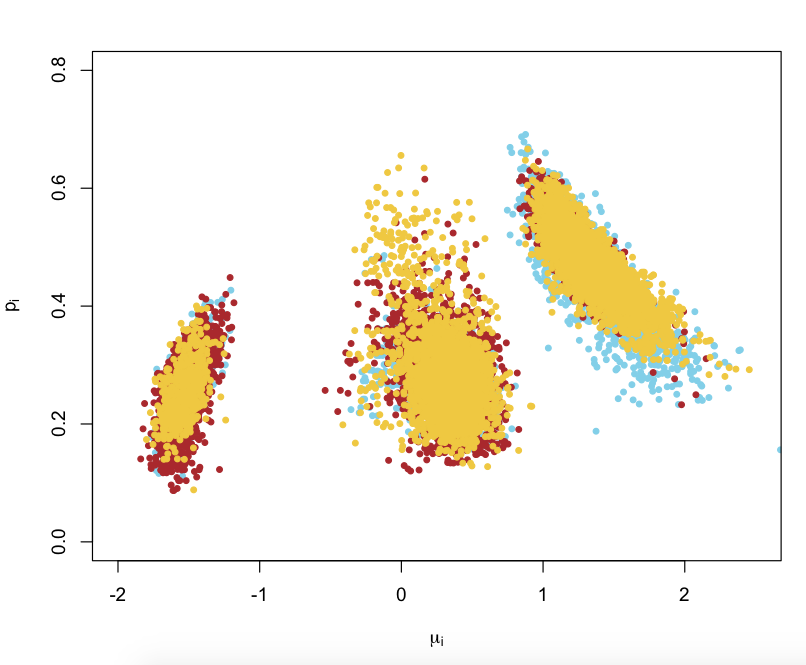 After presenting this work in both London and Lenzerheide, Kaniav Kamary, Kate Lee and I arXived and submitted our paper on a new parametrisation of location-scale mixtures. Although it took a long while to finalise the paper, given that we came with the original and central idea about a year ago, I remain quite excited by this new representation of mixtures, because the use of a global location-scale (hyper-)parameter doubling as the mean-standard deviation for the mixture itself implies that all the other parameters of this mixture model [beside the weights] belong to the intersection of a unit hypersphere with an hyperplane. [Hence the title above I regretted not using for the poster at MCMskv!]
After presenting this work in both London and Lenzerheide, Kaniav Kamary, Kate Lee and I arXived and submitted our paper on a new parametrisation of location-scale mixtures. Although it took a long while to finalise the paper, given that we came with the original and central idea about a year ago, I remain quite excited by this new representation of mixtures, because the use of a global location-scale (hyper-)parameter doubling as the mean-standard deviation for the mixture itself implies that all the other parameters of this mixture model [beside the weights] belong to the intersection of a unit hypersphere with an hyperplane. [Hence the title above I regretted not using for the poster at MCMskv!] This realisation that using a (meaningful) hyperparameter (μ,σ) leads to a compact parameter space for the component parameters is important for inference in such mixture models in that the hyperparameter (μ,σ) is easily estimated from the entire sample, while the other parameters can be studied using a non-informative prior like the Uniform prior on the ensuing compact space. This non-informative prior for mixtures is something I have been seeking for many years, hence my on-going excitement! In the mid-1990‘s, we looked at a Russian doll type parametrisation with Kerrie Mengersen that used the “first” component as defining the location-scale reference for the entire mixture. And expressing each new component as a local perturbation of the previous one. While this is a similar idea than the current one, it falls short of leading to a natural non-informative prior, forcing us to devise a proper prior on the variance that was a mixture of a Uniform U(0,1) and of an inverse Uniform 1/U(0,1). Because of the lack of compactness of the parameter space. Here, fixing both mean and variance (or even just the variance) binds the mixture parameter to an ellipse conditional on the weights. A space that can be turned into the unit sphere via a natural reparameterisation. Furthermore, the intersection with the hyperplane leads to a closed form spherical reparameterisation. Yay!
This realisation that using a (meaningful) hyperparameter (μ,σ) leads to a compact parameter space for the component parameters is important for inference in such mixture models in that the hyperparameter (μ,σ) is easily estimated from the entire sample, while the other parameters can be studied using a non-informative prior like the Uniform prior on the ensuing compact space. This non-informative prior for mixtures is something I have been seeking for many years, hence my on-going excitement! In the mid-1990‘s, we looked at a Russian doll type parametrisation with Kerrie Mengersen that used the “first” component as defining the location-scale reference for the entire mixture. And expressing each new component as a local perturbation of the previous one. While this is a similar idea than the current one, it falls short of leading to a natural non-informative prior, forcing us to devise a proper prior on the variance that was a mixture of a Uniform U(0,1) and of an inverse Uniform 1/U(0,1). Because of the lack of compactness of the parameter space. Here, fixing both mean and variance (or even just the variance) binds the mixture parameter to an ellipse conditional on the weights. A space that can be turned into the unit sphere via a natural reparameterisation. Furthermore, the intersection with the hyperplane leads to a closed form spherical reparameterisation. Yay!
While I do not wish to get into the debate about the [non-]existence of “non-informative” priors at this stage, I think being able to using the invariant reference prior π(μ,σ)=1/σ is quite neat here because the inference on the mixture parameters should be location and scale equivariant. The choice of the prior on the remaining parameters is of lesser importance, the Uniform over the compact being one example, although we did not study in depth this impact, being satisfied with the outputs produced from the default (Uniform) choice.
From a computational perspective, the new parametrisation can be easily turned into the old parametrisation, hence leads to a closed-form likelihood. This implies a Metropolis-within-Gibbs strategy can be easily implemented, as we did in the derived Ultimixt R package. (Which programming I was not involved in, solely suggesting the name Ultimixt from ultimate mixture parametrisation, a former title that we eventually dropped off for the paper.)
Discussing the paper at MCMskv was very helpful in that I got very positive feedback about the approach and superior arguments to justify the approach and its appeal. And to think about several extensions outside location scale families, if not in higher dimensions which remain a practical challenge (in the sense of designing a parametrisation of the covariance matrices in terms of the global covariance matrix).
