 [Here is my discussion on the paper “A Unified Framework for De-Duplication and Population Size Estimation” by [my friends] Andrea Tancredi, Rebecca Steorts, and Brunero Liseo, to appear on the June 2020 issue of Bayesian Analysis. The deadline is 24 April. Discussions are to be submitted to BA as regular submissions.]
[Here is my discussion on the paper “A Unified Framework for De-Duplication and Population Size Estimation” by [my friends] Andrea Tancredi, Rebecca Steorts, and Brunero Liseo, to appear on the June 2020 issue of Bayesian Analysis. The deadline is 24 April. Discussions are to be submitted to BA as regular submissions.]
Congratulations to the authors, for this paper that expand the modelling of populations investigated by faulty surveys, a poor quality feature that applies to extreme cases like Syria casualties. And possibly COVID-19 victims.
The model considered in this paper, as given by (2.1), is a latent variable model which appears as hyper-parameterised in the sense it involves a large number of parameters and latent variables. First, this means it is essentially intractable outside a Bayesian resolution. Second, within the Bayesian perspective, it calls for identifiability and consistency questions, namely which fraction of the unknown entities is identifiable and which fraction can be consistently estimated, eventually severing the dependence on the prior modelling. Personal experiences with capture-recapture models on social data like drug addict populations showed me that prior choices often significantly drive posterior inference on the population size. Here, it seems that the generative distortion mechanism between registry of individuals and actual records is paramount.
“We now investigate an alternative aspect of the uniform prior distribution of λ given N.”
Since the practical application stressed in the title, namely some of civil casualties in Syria, interrogations take a more topical flavour as one wonders at the connection between the model and the actual data, between the prior modelling and the available prior information. It is however not the strategy adopted in the paper, which instead proposes a generic prior modelling that could be deemed to be non-informative. I find the property that conditioning on the list sizes eliminates the capture probabilities and the duplication rates quite amazing, reminding me indeed of similar properties for conjugate mixtures, although we found the property hard to exploit from a computational viewpoint. And that the hit-miss model provides computationally tractable marginal distributions for the cluster observations.
“Several records of the VDC data set represent unidentified victims and report only the date of death or do not have the first name and report only the relationship with the head of the family.”
This non-informative choice is however quite informative in the misreporting mechanism and does not address the issue that it presumably is misspecified. It indeed makes the assumption that individual label and type of record are jointly enough to explain the probability of misreporting the exact record. In practical cases, it seems more realistic that the probability to appear in a list depends on the characteristics of an individual, hence far from being uniform as well as independent from one list to the next. The same applies to the probability of being misreported. The alternative to the uniform allocation of individuals to lists found in (3.3) remains neutral to the reasons why (some) individuals are missing from (some) lists. No informative input is indeed made here on how duplicates could appear or on how errors are made in registering individuals. Furthermore, given the high variability observed in inferring the number of actual deaths covered by the collection of the two lists, it would have been of interest to include a model comparison assessment, especially when contemplating the clash between the four posteriors in Figure 4.
The implementation of a manageable Gibbs sampler in such a convoluted model is quite impressive and one would welcome further comments from the authors on its convergence properties, since it is facing a large dimensional space. Are there theoretical or numerical irreducibility issues for instance, created by the discrete nature of some latent variables as in mixture models?
 Morning of diverse short talks. First talk by Bei Jiang (Edmonton) on locally processed privacy for quantile estimation, which relates very much to our ongoing research with Stan, who is starting his ERC funded PhD on privacy. Randomised response, in having a positive probability of replacing indicators in the empirical cdf by a random or perturbed version whose bias can be corrected. I may have overdone the similarity though in confusing users with agents. Followed by a hacking foray by Joel Reardon (Calgary) into how much information is transmitted by apps on completely unrelated phone activity. (Moral: Never send a bug report.)
Morning of diverse short talks. First talk by Bei Jiang (Edmonton) on locally processed privacy for quantile estimation, which relates very much to our ongoing research with Stan, who is starting his ERC funded PhD on privacy. Randomised response, in having a positive probability of replacing indicators in the empirical cdf by a random or perturbed version whose bias can be corrected. I may have overdone the similarity though in confusing users with agents. Followed by a hacking foray by Joel Reardon (Calgary) into how much information is transmitted by apps on completely unrelated phone activity. (Moral: Never send a bug report.)
 Before, I had a rather nice early morning in woods on top of Okanagan Lake, crossing many white tailed deer, hopefully no ticks!, as well as No trespassing signs. And a quick and c…ool swim in the Lake 20⁰ waters. No sign of the large
Before, I had a rather nice early morning in woods on top of Okanagan Lake, crossing many white tailed deer, hopefully no ticks!, as well as No trespassing signs. And a quick and c…ool swim in the Lake 20⁰ waters. No sign of the large 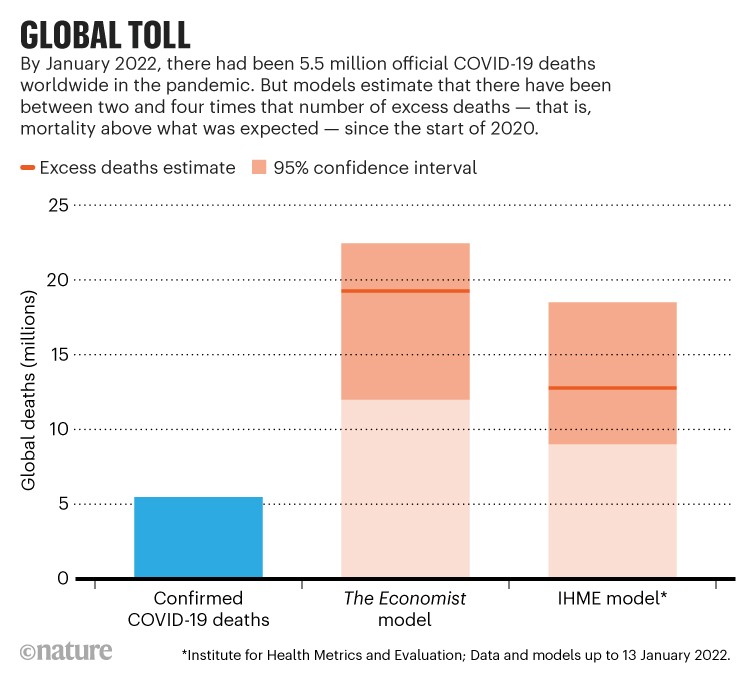


{kind=link}