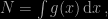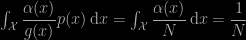Yet another paper that addresses the approximation of the marginal likelihood by a truncated harmonic mean, a popular theme of mine. A 2020 paper by Johannes Reich, entitled Estimating marginal likelihoods from the posterior draws through a geometric identity and published in Monte Carlo Methods and Applications.
The geometric identity it aims at exploiting is that

for any (positive volume) compact set $A$. This is exactly the same identity as in an earlier and uncited 2017 paper by Ana Pajor, with the also quite similar (!) title Estimating the Marginal Likelihood Using the Arithmetic Mean Identity and which I discussed on the ‘Og, linked with another 2012 paper by Lenk. Also discussed here. This geometric or arithmetic identity is again related to the harmonic mean correction based on a HPD region A that Darren Wraith and myself proposed at MaxEnt 2009. And that Jean-Michel and I presented at Frontiers of statistical decision making and Bayesian analysis in 2010.
In this avatar, the set A is chosen close to an HPD region, once more, with a structure that allows for an exact computation of its volume. Namely an ellipsoid that contains roughly 50% of the simulations from the posterior (rather than our non-intersecting union of balls centered at the 50% HPD points), which assumes a Euclidean structure of the parameter space (or, in other words, depends on the parameterisation)In the mixture illustration, the author surprisingly omits Chib’s solution, despite symmetrised versions avoiding the label (un)switching issues. . What I do not get is how this solution gets around the label switching challenge in that set A remains an ellipsoid for multimodal posteriors, which means it either corresponds to a single mode [but then how can a simulation be restricted to a “single permutation of the indicator labels“?] or it covers all modes but also the unlikely valleys in-between.