 Juho Piironen and Aki Vehtari just arXived a paper on variable selection that relates to two projection papers we wrote in the 1990’s with Costas Goutis (who died near Seattle in a diving accident on July 1996) and Jérôme Dupuis… Except that they move to the functional space of Gaussian processes. The covariance function in a Gaussian process is indeed based on a distance between observations, which are themselves defined as a vector of inputs. Some of which matter and some of which do not matter in the kernel value. When rescaling the distance with “length-scales” for all variables, one could think that non-significant variates have very small scales and hence bypass the need for variable selection but this is not the case as those coefficients react poorly to non-linearities in the variates… The paper thus builds a projective structure from a reference model involving all input variables.
Juho Piironen and Aki Vehtari just arXived a paper on variable selection that relates to two projection papers we wrote in the 1990’s with Costas Goutis (who died near Seattle in a diving accident on July 1996) and Jérôme Dupuis… Except that they move to the functional space of Gaussian processes. The covariance function in a Gaussian process is indeed based on a distance between observations, which are themselves defined as a vector of inputs. Some of which matter and some of which do not matter in the kernel value. When rescaling the distance with “length-scales” for all variables, one could think that non-significant variates have very small scales and hence bypass the need for variable selection but this is not the case as those coefficients react poorly to non-linearities in the variates… The paper thus builds a projective structure from a reference model involving all input variables.
“…adding some irrelevant inputs is not disastrous if the model contains a sparsifying prior structure, and therefore, one can expect to lose less by using all the inputs than by trying to differentiate between the relevant and irrelevant ones and ignoring the uncertainty related to the left-out inputs.”
While I of course appreciate this avatar to our original idea (with some borrowing from McCulloch and Rossi, 1992), the paper reminds me of some of the discussions and doubts we had about the role of the reference or super model that “anchors” the projections, as there is no reason for that reference model to be a better one. It could be that an iterative process where the selected submodel becomes the reference for the next iteration could enjoy better performances. When I first presented this work in Cagliari, in the late 1990s, one comment was that the method had no theoretical guarantee like consistency. Which is correct if the minimum distance is not evolving (how quickly?!) with the sample size n. I also remember the difficulty Jérôme and I had in figuring out a manageable forward-backward exploration of the (huge) set of acceptable subsets of variables. Random walk exploration and RJMCMC are unlikely to solve this problem.

")
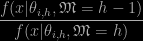
 is the model index,
is the model index, ‘s are simulated from the posterior under model h,
‘s are simulated from the posterior under model h, only considers the h-1 first components of
only considers the h-1 first components of 