 Analytic Posteriors for Pearson’s Correlation Coefficient was arXived yesterday by Alexander Ly , Maarten Marsman, and Eric-Jan Wagenmakers from Amsterdam, with whom I recently had two most enjoyable encounters (and dinners!). And whose paper on Jeffreys’ Theory of Probability I recently discussed in the Journal of Mathematical Psychology.
Analytic Posteriors for Pearson’s Correlation Coefficient was arXived yesterday by Alexander Ly , Maarten Marsman, and Eric-Jan Wagenmakers from Amsterdam, with whom I recently had two most enjoyable encounters (and dinners!). And whose paper on Jeffreys’ Theory of Probability I recently discussed in the Journal of Mathematical Psychology.
The paper re-analyses Bayesian inference on the Gaussian correlation coefficient, demonstrating that for standard reference priors the posterior moments are (surprisingly) available in closed form. Including priors suggested by Jeffreys (in a 1935 paper), Lindley, Bayarri (Susie’s first paper!), Berger, Bernardo, and Sun. They all are of the form
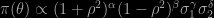
and the corresponding profile likelihood on ρ is in “closed” form (“closed” because it involves hypergeometric functions). And only depends on the sample correlation which is then marginally sufficient (although I do not like this notion!). The posterior moments associated with those priors can be expressed as series (of hypergeometric functions). While the paper is very technical, borrowing from the Bateman project and from Gradshteyn and Ryzhik, I like it if only because it reminds me of some early papers I wrote in the same vein, Abramowitz and Stegun being one of the very first books I bought (at a ridiculous price in the bookstore of Purdue University…).
Two comments about the paper: I see nowhere a condition for the posterior to be proper, although I assume it could be the n>1+γ−2α+δ constraint found in Corollary 2.1 (although I am surprised there is no condition on the coefficient β). The second thing is about the use of this analytic expression in simulations from the marginal posterior on ρ: Since the density is available, numerical integration is certainly more efficient than Monte Carlo integration [for quantities that are not already available in closed form]. Furthermore, in the general case when β is not zero, the cost of computing infinite series of hypergeometric and gamma functions maybe counterbalanced by a direct simulation of ρ and both variance parameters since the profile likelihood of this triplet is truly in closed form, see eqn (2.11). And I will not comment the fact that Fisher ends up being the most quoted author in the paper!

